Kuzushiji-MNIST[18]-[21]は日本の古典からとったひらがなのくずし字のデータセットです。
以下の10字を同数含んでいます。
お, き, す, つ, な, は, ま, や, れ, を
60000個の訓練データと10000個テストデータから成ります。
各データは28x28ピクセルのモノクロ画像です。
図10-1にテストデータの各文字の最初の20個の画像を示します。
現在使われていない変体仮名[22](1900年の学校令で廃止されたひらがな)が多数含まれています。
したがって、複数の字体が同じ回答になるという特徴があります。
図10-2に自作CNNの正解率を示します。
CNN6とCNN8はほぼ同じであり、CNN4より勝ります。
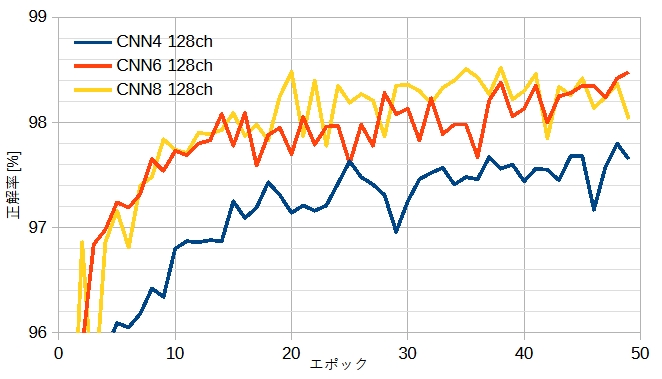
図10-3にその他のモデルの正解率を示します。
自作ResNetの正解率がその他のモデルよりより少し高くなり、自作CNNと同等です。
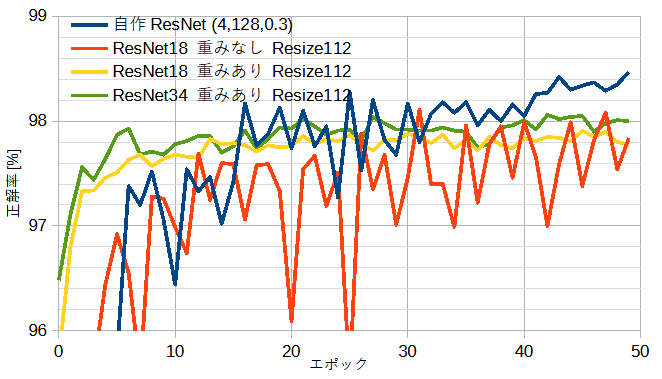
図10-4にテスト結果を示します。テストデータは最初の600個です。
赤字は上が正解、下が誤回答です。



図10-5に不正解回答のすべてを示します。

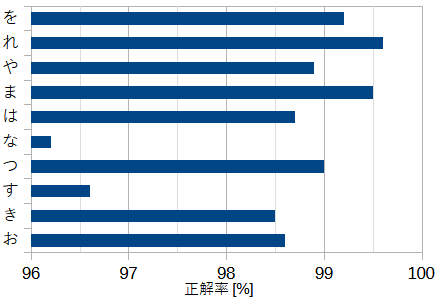
図10-6にラベル別の正解率を示します。"な,す"の正解率が低いことがわかります。