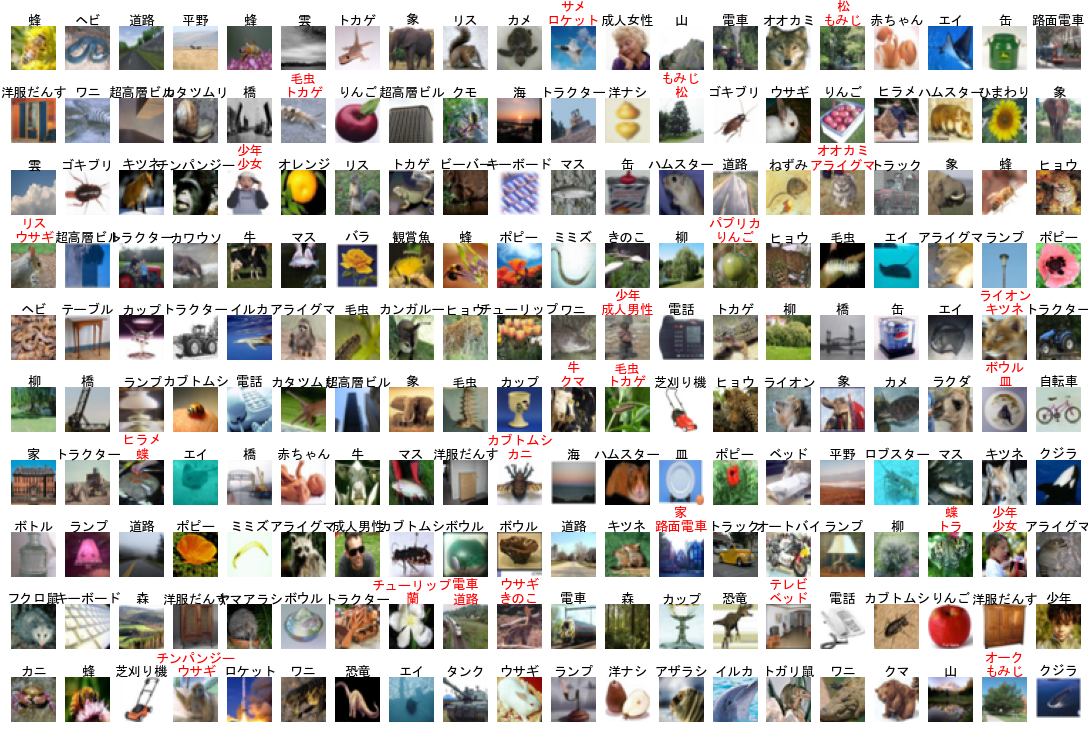
CIFAR-100[23]は100種類の画像データセットです。
50000個の訓練データと10000個のテストデータから成ります。
各データは32x32ピクセルのカラー画像です。
図12-1にテストデータの各種類の1個の画像を示します。
32x32ピクセルなので不鮮明な画像がたくさんあります。
図12-2に自作CNNの正解率を示します。
正解率を上げるにはブロック数を大きくするよりチャンネル数を大きくするほうが効果があります。
ただしCIFAR-10と比べて画像の種類が多いので正解率は大きく下がります。
正解率の最高は70.1%です。
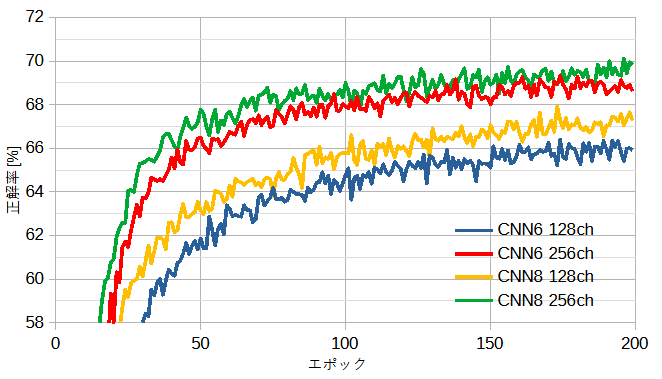
図12-3に自作ResNetの正解率を示します。
()内はブロック数とチャンネル数です。
ブロック数を大きくしても正解率はあまり変わりません。
正解率の最高は66.8%であり、自作CNNと比べて少し低くなります。
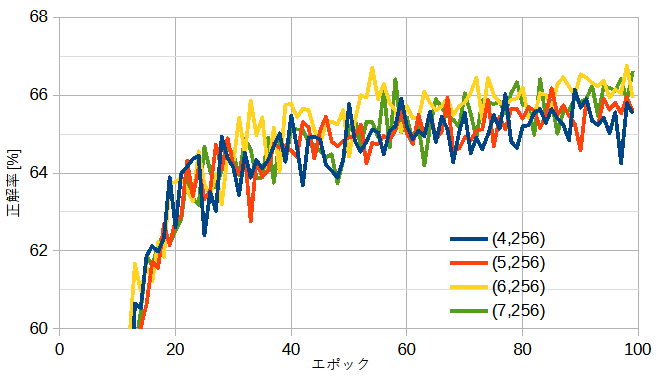
図12-4に公開ResNet(重みなし)の正解率を示します。
過学習のために損失が上昇に転じ、正解率も上がりません。
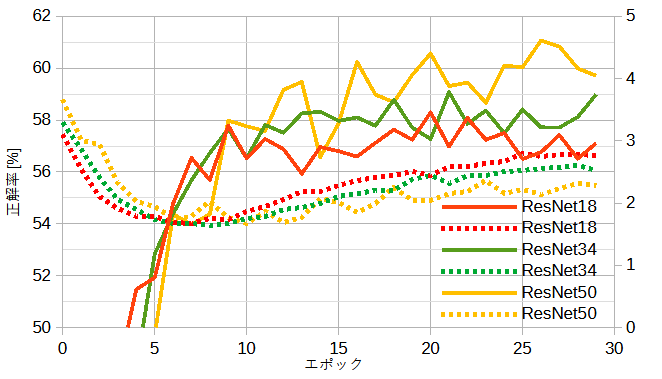
図12-5に公開ResNet(重みあり)の正解率を示します。
他のモデルと比べて正解率が大幅に上がり、
ネットワークが深くなるとさらに正解率が上がります。
CIFAR-100において高い正解率を得るには、
ネットワークを深くすると同時に過学習を防ぎながらパラメーターを高度にチューニングすることが必要です。
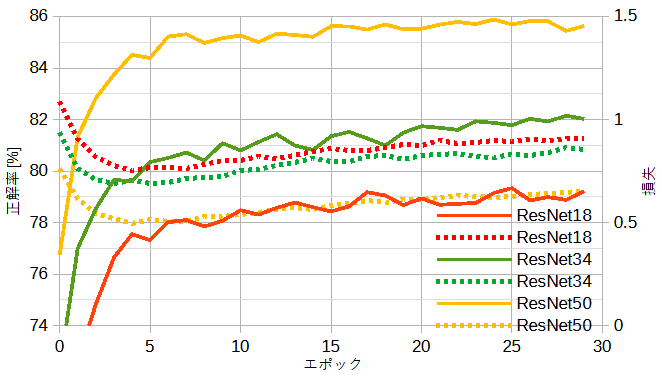
図12-6にResNet50(重みあり)においてパラメーターを変えたときの正解率を示します。
図中の数字は(Resize, lr, momentum)です。
正解率は最高86.09%です。
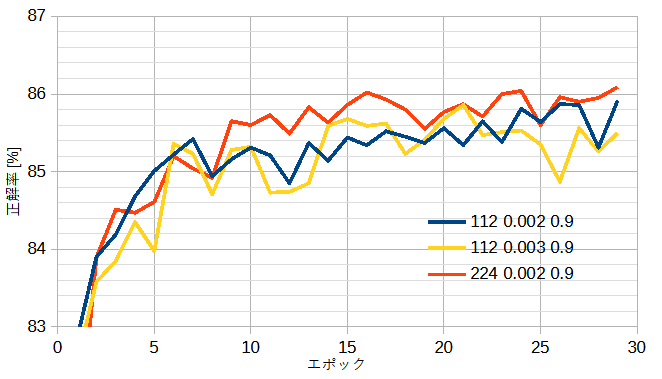
図12-7にテスト結果を示します。テストデータは最初の600個です。
赤字は上が正解、下が誤回答です。
32x32ピクセルなので不鮮明な画像がたくさんあります。