Kuzushiji-49[18]-[21]は日本の古典からとったひらがなのくずし字のデータセットです。
以下の49字から成ります。
あ,い,う,え,お,か,き,く,け,こ,さ,し,す,せ,そ,
た,ち,つ,て,と,な,に,ぬ,ね,の,は,ひ,ふ,へ,ほ,
ま,み,む,め,も,や,ゆ,よ,ら,り,る,れ,ろ,わ,ゐ,
ゑ,を,ん,ゝ
232365個の訓練データと38547個のテストデータから成ります。
各データは28x28ピクセルのモノクロ画像です。
Kuzushiji-MNISTと比べると、文字の数が10から49に増え、全体のデータ数が増え、
文字によってデータ数が不均一になっています。
また、Kuzushiji-MNISTと同じく変体仮名を多数含んでいます。
図13-1にテストデータの各文字の最初の20個の画像を示します。
図13-2に自作CNNの正解率を示します。
文字によってデータ数が変わりますが、
ここでは「正解率=正解テストデータ数/全テストデータ数」としています。
(a)128ch一定のとき、CNN6<CNN8=CNN10です。
(b)CNN8一定のとき、チャンネル数=128~256でほぼ一定です。
最高の正解率は97.50%です。
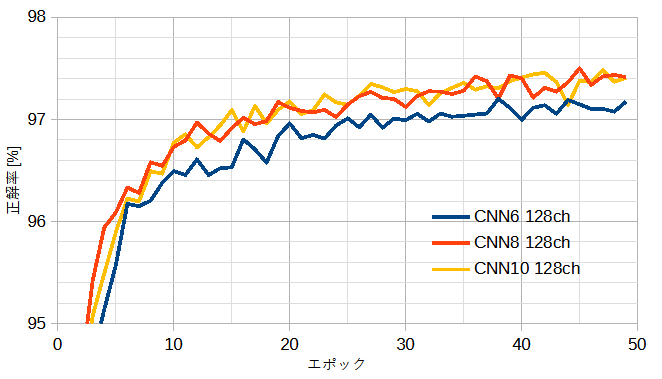
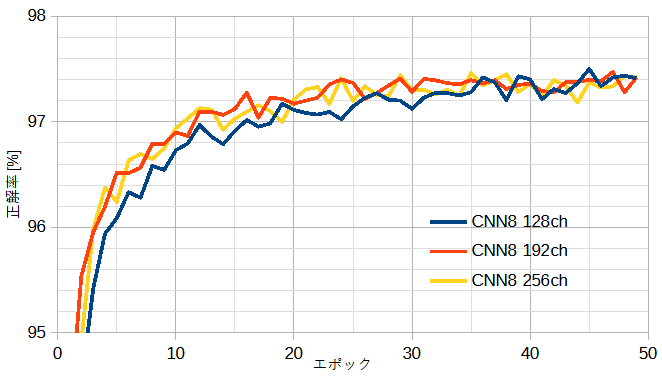
図13-2 自作CNNの正解率(Adam, 前処理なし, ドロップアウト0.3, ミニバッチ50)
図13-3に自作ResNetの正解率を示します。
()内はブロック数とチャンネル数です。
自作CNNとほぼ同等の正解率です。
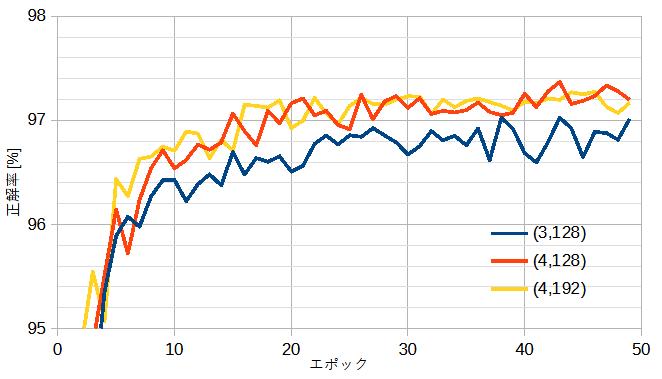
図13-4に公開ResNet(重みなし)の正解率と損失を示します。
自作CNNと比べて正解率が1%程度下がります。
ドロップアウトと前処理のリサイズを行っていないことが原因と思われます。
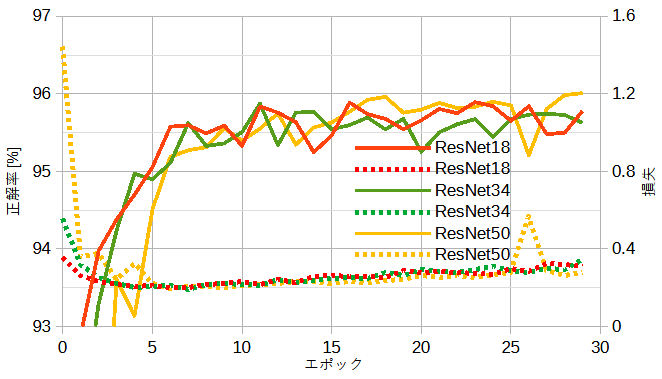
図13-5に公開ResNet(重みあり)の正解率と損失を示します。
自作CNNと比べて正解率が1%程度下がります。
ドロップアウトと前処理のリサイズを行っていないことが原因と思われます。
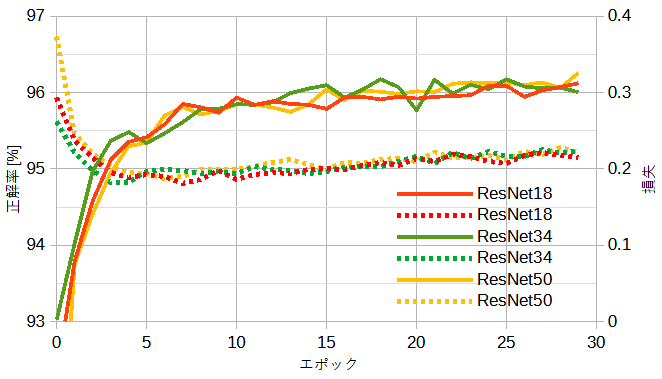
図13-6にテスト結果を示します。テストデータは最初の600個です。
赤字は上が正解、下が誤回答です。



図13-7に誤回答の最初の200個を示します。

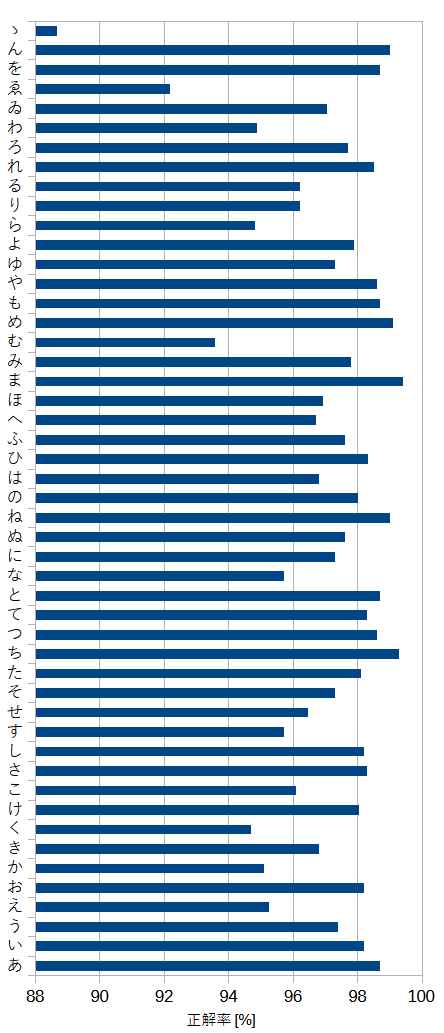
図13-8にラベル別の正解率を示します。"ゝ"を除けば正解率は92%以上になっています。