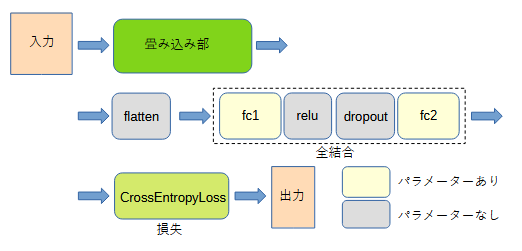
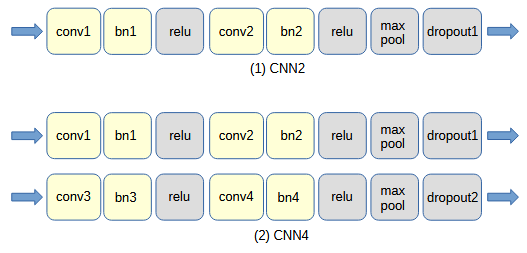
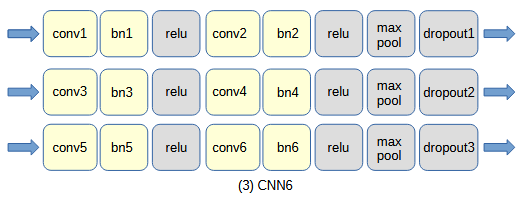
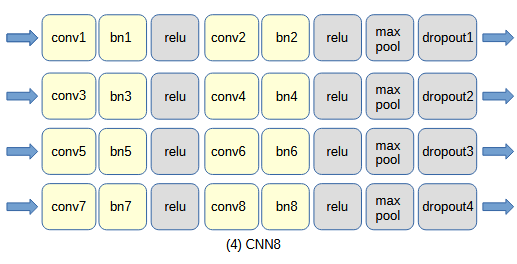
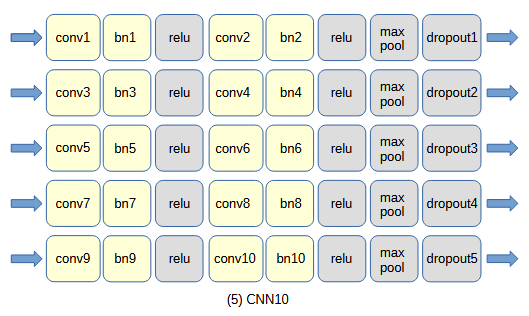
図3-1 自作CNNのネットワーク構成
CNN (Convolution Neural Network) の構成として、
自作CNN、自作ResNet、公開ResNetの3通りを考えます。
ソースコードCNN.py内の変数MODEL=0/1/2で選択します。
図3-1に自作CNNのネットワーク構成を示します[3]。
畳み込み部については下の(1)~(4)の4通りを考え、それぞれCNN2/CNN4/CNN6/CNN8と呼びます。
畳み込み部は畳み込み(conv)、バッチ正規化(bn)、ReLU活性化関数(relu)、
最大プーリング(max pool)、ドロップアウト(dropout)から成ります。
その後全結合(fc)部を通ります。
多値分類であるために損失にはCrossEntropyLoss関数を用います。
図3-1 自作CNNのネットワーク構成
畳み込みの出力サイズは次式で計算されます。
出力サイズ = [(入力サイズ + 2*パディング - カーネルサイズ) / ストライド] + 1
ここで、入力サイズ=N、パディング=1、カーネルサイズ=3、ストライド=1 とすると
出力サイズ = [(N + 2*1 - 3) / 1] + 1 = N
となり入力サイズと同じになります。
プーリングのサイズ=2とするとプーリングを行うごとに画素サイズは半分になります。
リスト3-1に自作CNNのネットワーククラスのソースコードを示します。
コンストラクタは以下の4個の引数を持ちます。
・in_size : 入力データの色数と縦横の画素数(MNISTのときは(1,28,28))
・channels : チャンネル数(配列の大きさ=畳み込み数)
・dropout : ドロップアウト確率(配列の大きさ=行数+1)
・out_classes : 出力分類数
リスト3-1 自作CNNのソースコード(CNN4, myCNN.py)
1 class CNN4(nn.Module):
2
3 def __init__(self, in_size, channels, dropout, out_classes):
4 super().__init__()
5
6 assert (len(in_size) == 3) and (len(channels) == 4) and (len(dropout) == 3)
7 out_pixel = (int(np.ceil(in_size[1] / 4)), int(np.ceil(in_size[2] / 4)))
8
9 self.conv1 = nn.Conv2d(in_size[0], channels[0], kernel_size=3, stride=1, padding=1)
10 self.conv2 = nn.Conv2d(channels[0], channels[1], kernel_size=3, stride=1, padding=1)
11 self.conv3 = nn.Conv2d(channels[1], channels[2], kernel_size=3, stride=1, padding=1)
12 self.conv4 = nn.Conv2d(channels[2], channels[3], kernel_size=3, stride=1, padding=1)
13 self.bn1 = nn.BatchNorm2d(channels[0])
14 self.bn2 = nn.BatchNorm2d(channels[1])
15 self.bn3 = nn.BatchNorm2d(channels[2])
16 self.bn4 = nn.BatchNorm2d(channels[3])
17 self.dropout1 = nn.Dropout(dropout[0])
18 self.dropout2 = nn.Dropout(dropout[1])
19 self.dropout3 = nn.Dropout(dropout[2])
20 self.relu = nn.ReLU(inplace=True)
21 self.maxpool = nn.MaxPool2d(2, ceil_mode=True)
22 self.flatten = nn.Flatten()
23 self.fc1 = nn.Linear(out_pixel[0] * out_pixel[1] * channels[-1], channels[-1])
24 self.fc2 = nn.Linear(channels[-1], out_classes)
25
26 self.features = nn.Sequential(
27 self.conv1, self.bn1, self.relu,
28 self.conv2, self.bn2, self.relu, self.maxpool, self.dropout1,
29 self.conv3, self.bn3, self.relu,
30 self.conv4, self.bn4, self.relu, self.maxpool, self.dropout2,
31 )
32
33 self.classifier = nn.Sequential(
34 self.fc1,
35 self.relu,
36 self.dropout3,
37 self.fc2,
38 )
39
40 def forward(self, x):
41 x = self.features(x)
42 x = self.flatten(x)
43 x = self.classifier(x)
44 return x
自作CNNのネットワークのprint文の出力(オプション)はリスト3-2の通りです。
ソースコードの記述そのままです。
リスト3-2 自作CNNのネットワークの出力(1)(CNN4, MNIST, 128チャンネル)
CNN4(
(conv1): Conv2d(1, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv4): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dropout1): Dropout(p=0.3, inplace=False)
(dropout2): Dropout(p=0.3, inplace=False)
(dropout3): Dropout(p=0.3, inplace=False)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc1): Linear(in_features=6272, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
(features): Sequential(
(0): Conv2d(1, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(7): Dropout(p=0.3, inplace=False)
(8): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): ReLU(inplace=True)
(11): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(12): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(13): ReLU(inplace=True)
(14): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(15): Dropout(p=0.3, inplace=False)
)
(classifier): Sequential(
(0): Linear(in_features=6272, out_features=128, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.3, inplace=False)
(3): Linear(in_features=128, out_features=10, bias=True)
)
)
自作CNNのsummary関数の出力(オプション)はリスト3-3の通りです。
"Output Shape"の最初の50はミニバッチサイズです。
PyTorchでsummary関数を使用するには、
Anaconda Prompt で下記を実行して torchinfo をインストールする必要があります。
$ conda install conda-forge::torchinfo
その後ソースコードCNN.pyに以下の2行を挿入します。
from torchinfo import summary (main関数定義の前)
summary(net, (50, 1, 28, 28)) (net作成の後、MNISTの場合)
summary関数の出力はSpyderのIPythonコンソールには行われないので、
Anaconda Prompt で下記のコマンドを実行する必要があります。
$ python CNN.py
リスト3-3 自作CNNのネットワークの出力(2)(CNN4, MNIST, 128チャンネル)
========================================================================================== Layer (type:depth-idx) Output Shape Param # ========================================================================================== CNN4 [50, 10] -- ├─Sequential: 1-1 [50, 128, 7, 7] 443,520 │ └─Conv2d: 2-1 [50, 128, 28, 28] 1,280 │ └─BatchNorm2d: 2-2 [50, 128, 28, 28] 256 ├─Sequential: 1-8 -- (recursive) │ └─ReLU: 2-3 [50, 128, 28, 28] -- ├─Sequential: 1-9 -- (recursive) │ └─Conv2d: 2-4 [50, 128, 28, 28] 147,584 │ └─BatchNorm2d: 2-5 [50, 128, 28, 28] 256 ├─Sequential: 1-8 -- (recursive) │ └─ReLU: 2-6 [50, 128, 28, 28] -- ├─Sequential: 1-9 -- (recursive) │ └─MaxPool2d: 2-7 [50, 128, 14, 14] -- │ └─Dropout: 2-8 [50, 128, 14, 14] -- │ └─Conv2d: 2-9 [50, 128, 14, 14] 147,584 │ └─BatchNorm2d: 2-10 [50, 128, 14, 14] 256 ├─Sequential: 1-8 -- (recursive) │ └─ReLU: 2-11 [50, 128, 14, 14] -- ├─Sequential: 1-9 -- (recursive) │ └─Conv2d: 2-12 [50, 128, 14, 14] 147,584 │ └─BatchNorm2d: 2-13 [50, 128, 14, 14] 256 ├─Sequential: 1-8 -- (recursive) │ └─ReLU: 2-14 [50, 128, 14, 14] -- ├─Sequential: 1-9 -- (recursive) │ └─MaxPool2d: 2-15 [50, 128, 7, 7] -- │ └─Dropout: 2-16 [50, 128, 7, 7] -- ├─Flatten: 1-10 [50, 6272] -- ├─Sequential: 1-11 [50, 10] -- │ └─Linear: 2-17 [50, 128] 802,944 │ └─ReLU: 2-18 [50, 128] -- │ └─Dropout: 2-19 [50, 128] -- │ └─Linear: 2-20 [50, 10] 1,290 ========================================================================================== Total params: 1,692,810 Trainable params: 1,692,810 Non-trainable params: 0 Total mult-adds (Units.GIGABYTES): 8.77 ========================================================================================== Input size (MB): 0.16 Forward/backward pass size (MB): 200.76 Params size (MB): 5.00 Estimated Total Size (MB): 205.91 ==========================================================================================
ResNetは層数が多いときの勾配消失問題を解決したネットワークです[5]-[8]。
図3-2に自作ResNetのネットワーク構成を示します。
任意個数のResNet単位blockが並びます。
ResNet単位blockはショートカット加算が特徴です。
図では1個のResNet単位blockが2個の畳み込みを含みます。
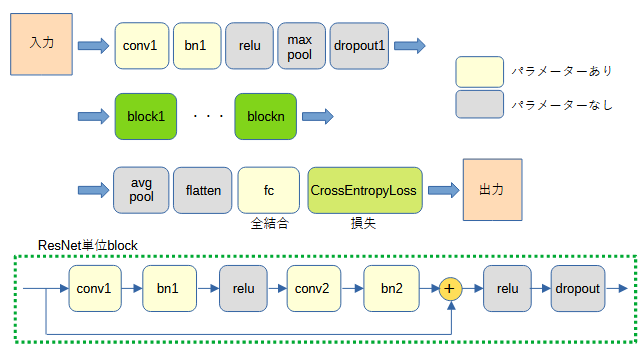
リスト3-4に自作ResNetのネットワーククラスのソースコードを示します。
コンストラクタは以下の引数を持ちます。
リスト3-4 自作ResNetのソースコード(myResNet.py)
1 class BasicBlock(nn.Module):
2
3 def __init__(self, channels, dropout):
4 super().__init__()
5
6 self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, stride=1, padding=1, bias=False)
7 self.bn1 = nn.BatchNorm2d(channels)
8 self.relu = nn.ReLU(inplace=True)
9 self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, stride=1, padding=1, bias=False)
10 self.bn2 = nn.BatchNorm2d(channels)
11 self.dropout1 = nn.Dropout(dropout)
12
13 def forward(self, x: torch.Tensor) -> torch.Tensor:
14 out = self.conv1(x)
15 out = self.bn1(out)
16 out = self.relu(out)
17 out = self.conv2(out)
18 out = self.bn2(out)
19 out += x # ResNet
20 out = self.relu(out)
21 out = self.dropout1(out)
22
23 return out
24
25 class ResNet(nn.Module):
26
27 def __init__(self, in_filters, num_blocks, channels, dropout, out_classes):
28 super().__init__()
29
30 self.conv1 = nn.Conv2d(in_filters, channels, kernel_size=3, stride=1, padding=1)#, bias=False)
31 self.bn1 = nn.BatchNorm2d(channels)
32 self.relu = nn.ReLU(inplace=True)
33 self.maxpool = nn.MaxPool2d(2, ceil_mode=True)
34 self.dropout1 = nn.Dropout(dropout)
35
36 self.blocks = nn.Sequential(*[BasicBlock(channels, dropout) for _ in range(num_blocks)])
37
38 self.avgpool = nn.AdaptiveAvgPool2d(1)
39 self.flatten = nn.Flatten()
40 self.fc = nn.Linear(channels, out_classes)
41
42 def forward(self, x):
43 x = self.conv1(x)
44 x = self.bn1(x)
45 x = self.relu(x)
46 x = self.maxpool(x)
47 x = self.dropout1(x)
48
49 x = self.blocks(x)
50
51 x = self.avgpool(x)
52 x = self.flatten(x)
53 x = self.fc(x)
54
55 return x
自作ResNetのネットワークのprint文の出力(オプション)はリスト3-5の通りです。
リスト3-5 自作ResNetのネットワークの出力(1)(MNIST、ブロック数=2、チャンネル数=128)
ResNet(
(conv1): Conv2d(1, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(dropout1): Dropout(p=0.3, inplace=False)
(blocks): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dropout1): Dropout(p=0.3, inplace=False)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dropout1): Dropout(p=0.3, inplace=False)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=1)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc): Linear(in_features=128, out_features=10, bias=True)
)
自作ResNetの summary(net, (50, 1, 28, 28)) 関数の出力(オプション)はリスト3-6の通りです。
"Output Shape"の最初の50はミニバッチサイズです。
リスト3-6 自作ResNetのネットワークの出力(2)(MNIST、ブロック数=2、チャンネル数=128)
========================================================================================== Layer (type:depth-idx) Output Shape Param # ========================================================================================== ResNet [50, 10] -- ├─Conv2d: 1-1 [50, 128, 28, 28] 1,280 ├─BatchNorm2d: 1-2 [50, 128, 28, 28] 256 ├─ReLU: 1-3 [50, 128, 28, 28] -- ├─MaxPool2d: 1-4 [50, 128, 14, 14] -- ├─Dropout: 1-5 [50, 128, 14, 14] -- ├─Sequential: 1-6 [50, 128, 14, 14] -- │ └─BasicBlock: 2-1 [50, 128, 14, 14] -- │ │ └─Conv2d: 3-1 [50, 128, 14, 14] 147,456 │ │ └─BatchNorm2d: 3-2 [50, 128, 14, 14] 256 │ │ └─ReLU: 3-3 [50, 128, 14, 14] -- │ │ └─Conv2d: 3-4 [50, 128, 14, 14] 147,456 │ │ └─BatchNorm2d: 3-5 [50, 128, 14, 14] 256 │ │ └─ReLU: 3-6 [50, 128, 14, 14] -- │ │ └─Dropout: 3-7 [50, 128, 14, 14] -- │ └─BasicBlock: 2-2 [50, 128, 14, 14] -- │ │ └─Conv2d: 3-8 [50, 128, 14, 14] 147,456 │ │ └─BatchNorm2d: 3-9 [50, 128, 14, 14] 256 │ │ └─ReLU: 3-10 [50, 128, 14, 14] -- │ │ └─Conv2d: 3-11 [50, 128, 14, 14] 147,456 │ │ └─BatchNorm2d: 3-12 [50, 128, 14, 14] 256 │ │ └─ReLU: 3-13 [50, 128, 14, 14] -- │ │ └─Dropout: 3-14 [50, 128, 14, 14] -- ├─AdaptiveAvgPool2d: 1-7 [50, 128, 1, 1] -- ├─Flatten: 1-8 [50, 128] -- ├─Linear: 1-9 [50, 10] 1,290 ========================================================================================== Total params: 593,674 Trainable params: 593,674 Non-trainable params: 0 Total mult-adds (Units.GIGABYTES): 5.83 ========================================================================================== Input size (MB): 0.16 Forward/backward pass size (MB): 160.57 Params size (MB): 2.37 Estimated Total Size (MB): 163.10 ==========================================================================================
PyTorchには多数のネットワークが組み込まれており簡単に使用することができます[5]。
それらは高度にチューニングされたパラメーター(weights:重み)を含んでいます。
公開ResNet(PyTorchに組み込まれたResNet)を使用するには、
下記の1~3行のいずれかを有効にしてください。
それぞれResNet18/ResNet34/ResNet50が有効になります。
なお、引数"weights=None"とすると学習済みのパラメーターは読み込まれずに自分で学習する必要があります。
公開ResNetはImageNet[9](224x224ピクセル, カラー, 1000分類)
向けに学習されているので4行目で出力分類数を変更することが必要です。
net = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
net = models.resnet34(weights=models.ResNet34_Weights.DEFAULT)
net = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
net.fc = nn.Linear(net.fc.in_features, len(strclasses))
ResNet18のprint文の出力はリスト3-7の通りです。
リスト3-7 ResNet18のネットワークの出力(1)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)
ResNet18の summary(net, (50, 3, 224, 224)) 関数の出力(オプション)はリスト3-8の通りです。
"Output Shape"の最初の50はミニバッチサイズです。
リスト3-8 ResNet18のネットワークの出力(2)
========================================================================================== Layer (type:depth-idx) Output Shape Param # ========================================================================================== ResNet [50, 10] -- ├─Conv2d: 1-1 [50, 64, 112, 112] 9,408 ├─BatchNorm2d: 1-2 [50, 64, 112, 112] 128 ├─ReLU: 1-3 [50, 64, 112, 112] -- ├─MaxPool2d: 1-4 [50, 64, 56, 56] -- ├─Sequential: 1-5 [50, 64, 56, 56] -- │ └─BasicBlock: 2-1 [50, 64, 56, 56] -- │ │ └─Conv2d: 3-1 [50, 64, 56, 56] 36,864 │ │ └─BatchNorm2d: 3-2 [50, 64, 56, 56] 128 │ │ └─ReLU: 3-3 [50, 64, 56, 56] -- │ │ └─Conv2d: 3-4 [50, 64, 56, 56] 36,864 │ │ └─BatchNorm2d: 3-5 [50, 64, 56, 56] 128 │ │ └─ReLU: 3-6 [50, 64, 56, 56] -- │ └─BasicBlock: 2-2 [50, 64, 56, 56] -- │ │ └─Conv2d: 3-7 [50, 64, 56, 56] 36,864 │ │ └─BatchNorm2d: 3-8 [50, 64, 56, 56] 128 │ │ └─ReLU: 3-9 [50, 64, 56, 56] -- │ │ └─Conv2d: 3-10 [50, 64, 56, 56] 36,864 │ │ └─BatchNorm2d: 3-11 [50, 64, 56, 56] 128 │ │ └─ReLU: 3-12 [50, 64, 56, 56] -- ├─Sequential: 1-6 [50, 128, 28, 28] -- │ └─BasicBlock: 2-3 [50, 128, 28, 28] -- │ │ └─Conv2d: 3-13 [50, 128, 28, 28] 73,728 │ │ └─BatchNorm2d: 3-14 [50, 128, 28, 28] 256 │ │ └─ReLU: 3-15 [50, 128, 28, 28] -- │ │ └─Conv2d: 3-16 [50, 128, 28, 28] 147,456 │ │ └─BatchNorm2d: 3-17 [50, 128, 28, 28] 256 │ │ └─Sequential: 3-18 [50, 128, 28, 28] 8,448 │ │ └─ReLU: 3-19 [50, 128, 28, 28] -- │ └─BasicBlock: 2-4 [50, 128, 28, 28] -- │ │ └─Conv2d: 3-20 [50, 128, 28, 28] 147,456 │ │ └─BatchNorm2d: 3-21 [50, 128, 28, 28] 256 │ │ └─ReLU: 3-22 [50, 128, 28, 28] -- │ │ └─Conv2d: 3-23 [50, 128, 28, 28] 147,456 │ │ └─BatchNorm2d: 3-24 [50, 128, 28, 28] 256 │ │ └─ReLU: 3-25 [50, 128, 28, 28] -- ├─Sequential: 1-7 [50, 256, 14, 14] -- │ └─BasicBlock: 2-5 [50, 256, 14, 14] -- │ │ └─Conv2d: 3-26 [50, 256, 14, 14] 294,912 │ │ └─BatchNorm2d: 3-27 [50, 256, 14, 14] 512 │ │ └─ReLU: 3-28 [50, 256, 14, 14] -- │ │ └─Conv2d: 3-29 [50, 256, 14, 14] 589,824 │ │ └─BatchNorm2d: 3-30 [50, 256, 14, 14] 512 │ │ └─Sequential: 3-31 [50, 256, 14, 14] 33,280 │ │ └─ReLU: 3-32 [50, 256, 14, 14] -- │ └─BasicBlock: 2-6 [50, 256, 14, 14] -- │ │ └─Conv2d: 3-33 [50, 256, 14, 14] 589,824 │ │ └─BatchNorm2d: 3-34 [50, 256, 14, 14] 512 │ │ └─ReLU: 3-35 [50, 256, 14, 14] -- │ │ └─Conv2d: 3-36 [50, 256, 14, 14] 589,824 │ │ └─BatchNorm2d: 3-37 [50, 256, 14, 14] 512 │ │ └─ReLU: 3-38 [50, 256, 14, 14] -- ├─Sequential: 1-8 [50, 512, 7, 7] -- │ └─BasicBlock: 2-7 [50, 512, 7, 7] -- │ │ └─Conv2d: 3-39 [50, 512, 7, 7] 1,179,648 │ │ └─BatchNorm2d: 3-40 [50, 512, 7, 7] 1,024 │ │ └─ReLU: 3-41 [50, 512, 7, 7] -- │ │ └─Conv2d: 3-42 [50, 512, 7, 7] 2,359,296 │ │ └─BatchNorm2d: 3-43 [50, 512, 7, 7] 1,024 │ │ └─Sequential: 3-44 [50, 512, 7, 7] 132,096 │ │ └─ReLU: 3-45 [50, 512, 7, 7] -- │ └─BasicBlock: 2-8 [50, 512, 7, 7] -- │ │ └─Conv2d: 3-46 [50, 512, 7, 7] 2,359,296 │ │ └─BatchNorm2d: 3-47 [50, 512, 7, 7] 1,024 │ │ └─ReLU: 3-48 [50, 512, 7, 7] -- │ │ └─Conv2d: 3-49 [50, 512, 7, 7] 2,359,296 │ │ └─BatchNorm2d: 3-50 [50, 512, 7, 7] 1,024 │ │ └─ReLU: 3-51 [50, 512, 7, 7] -- ├─AdaptiveAvgPool2d: 1-9 [50, 512, 1, 1] -- ├─Linear: 1-10 [50, 10] 5,130 ========================================================================================== Total params: 11,181,642 Trainable params: 11,181,642 Non-trainable params: 0 Total mult-adds (Units.GIGABYTES): 90.68 ========================================================================================== Input size (MB): 30.11 Forward/backward pass size (MB): 1986.97 Params size (MB): 44.73 Estimated Total Size (MB): 2061.81 ==========================================================================================