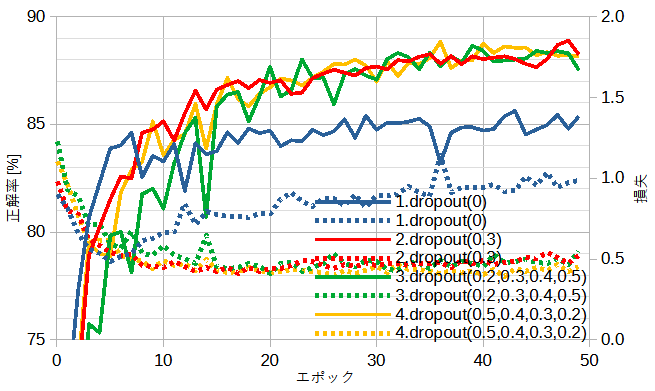
計算プログラムはいくつかのハイパーパラメーターを持っています。
ここではハイパーパラメーターの最適値について考察します。
データセットとしては比較的難しく正解率の低いCIFAR-10を取り上げます。
図5-1にドロップアウトの確率と正解率の関係を示します。
以下では正解率とはすべてテストデータに関するものです。
ドロップアウトの確率について以下の4通りを考えています。
[3]ではケース3がよいと書いてありますが必ずしもそうではないです。
[6]の公開ResNetはデータセットの大きなImageNetを対象にしているために過学習は起こりにくいのでドロップアウトは使用していませんが、
データセットが大きくないときはドロップアウトは必要になるかもしれないと書かれています。
図5-2にミニバッチの大きさと正解率の関係を示します。
ミニバッチの大きさを25~200と変えても収束の速さと最終的な正解率はほぼ同じです。
以下では比較的正解率の変動の少ないミニバッチサイズ=50とします。
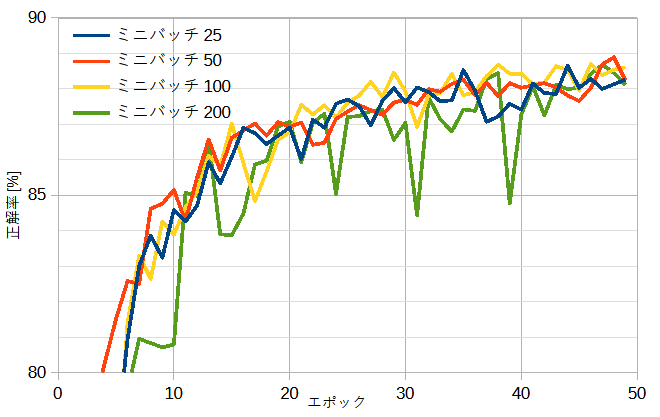
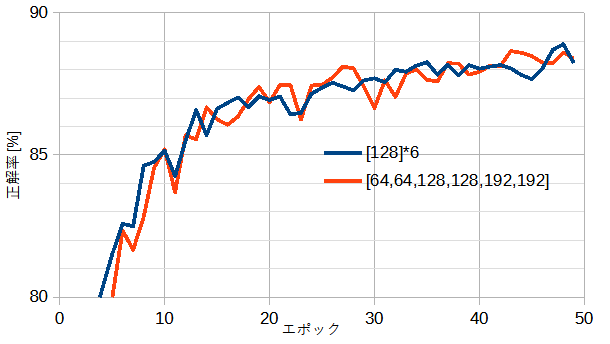
図5-3にCNNのチャンネル数と正解率の関係を示します。
チャンネル数一定と層が進むごとに大きくする2通りを考えています。
図から両者の性能はほぼ同じと言えます。
ハイパーパラメータの数は少ないほど扱いやすいので、
以下ではチャンネル数一定とします。
最適な層の数とチャンネル数は問題の難しさによります。
公開ResNetは層が進むごとにチャンネル数を大きくしていますが、
必ずしもその必要はありません。
学習を行う前にデータセットの画像を加工することを前処理(transform)と呼びます。
torchvision.transformsには多数の前処理が登録されており簡単に使用することができます。
ここでは左右反転(RandomHorizontalFlip関数)と正規化(Normalize関数)の2つを考えます。
図5-4に前処理と正解率の関係を示します。
前処理によって正解率が上がることがわかります。
左右反転の方が効果が大きいと思われます。
問題が難しくないときは(正解率が十分高いときは)前処理の有意な効果が見られないこともあります。
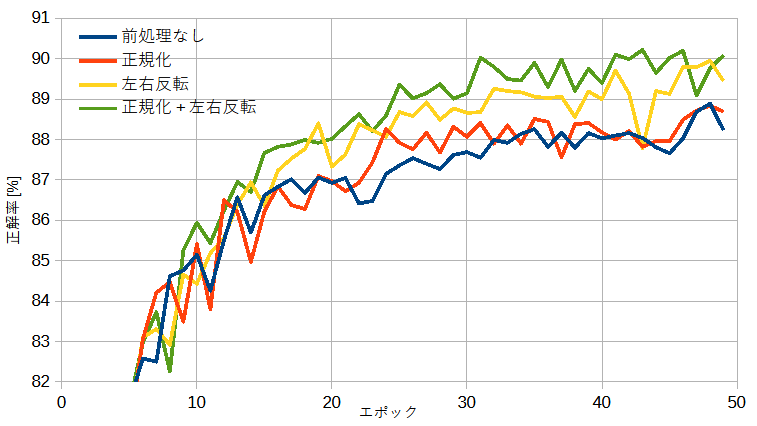
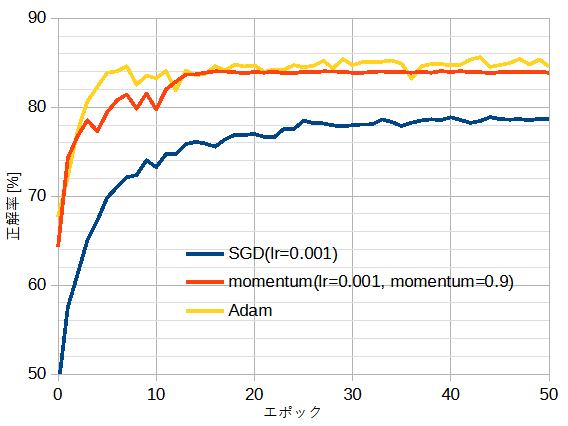
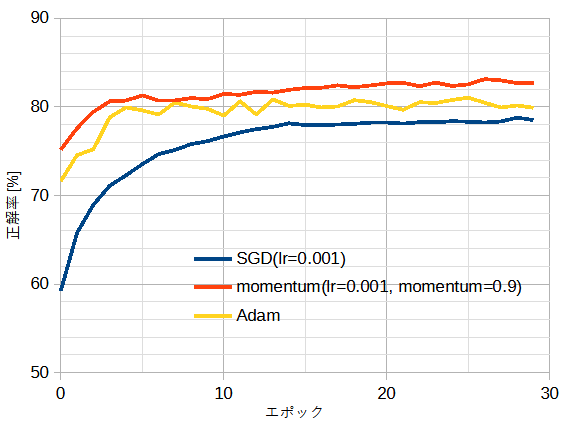
図5-5と図5-6に最適化関数と正解率の関係を示します。
それぞれ自作CNNとResNet18重みありのときです。
図5-5から、ゼロから(正確にはランダムから)学習するときはAdamが適しており、
図5-6から、高度にチューニングされた公開ResNetから追加学習するときはmomentumが適していることがわかります[3]。
表5-1にモデルごとに最適な最適化関数を示します。
| ケース | モデル | 最適化関数 |
|---|---|---|
| 1 | 自作CNN | Adam |
| 2 | 自作ResNet | Adam |
| 3 | 公開ResNet重みなし | Adam |
| 4 | 公開ResNet重みあり | momentum |
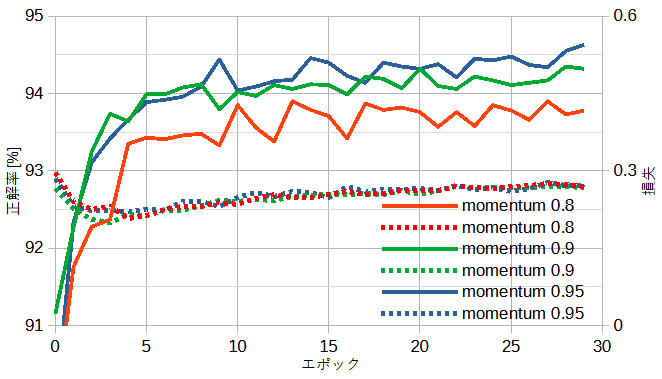
前節の通り、公開ResNet(重みあり)ではmomentum法が適しています。
momentum法は学習率(lr)と係数(momentum)の2つの引数を持っています。
図5-7にmomentum法の係数と正解率の関係を示します。
係数が大きいほど正解率が高いことがわかります(1は不可)。
学習率についてはデータセットごとに考察します。
各モデルのGPUの計算時間を表5-2~表5-4に示します。
計算時間は固有部分とパラメーターに比例する部分の和になります。
計算時間はデータセットの大きさによっても変わります。
| モデル | 64ch | 128ch | 192ch | 256ch |
|---|---|---|---|---|
| CNN4 | 11秒 | 13秒 | 26秒 | 38秒 |
| CNN6 | 11秒 | 14秒 | 28秒 | 40秒 |
| CNN8 | 12秒 | 15秒 | 29秒 | 42秒 |
| モデル | 64ch | 128ch | 192ch | 256ch |
|---|---|---|---|---|
| 2ブロック | 10秒 | 11秒 | 18秒 | 27秒 |
| 4ブロック | 12秒 | 16秒 | 30秒 | 46秒 |
| 6ブロック | 13秒 | 23秒 | 42秒 | 65秒 |
| モデル | Resize32 | Resize64 | Resize112 | Resize224 |
|---|---|---|---|---|
| ResNet18 | 16秒 | 20秒 | 32秒 | 106秒 |
| ResNet34 | 21秒 | 27秒 | 50秒 | 177秒 |
| ResNet50 | 27秒 | 39秒 | 84秒 | 314秒 |