
MNIST[13][14]は画像分類問題の最も基本的なデータセットです。
0-9の手書き文字を判定します。
60000枚の画像で訓練し、10000枚の画像でテストしてその正解率を評価します。
画像は28x28ピクセルのモノクロ(グレイスケール)です。
訓練とテストに用いる画像とラベルの集まりをデータセットと呼びます。
リスト6-1にMNISTデータセットを読み込むソースコードを示します。
torchvision.datasetsに含まれるデータセットを読み込む方法はほぼ共通ですが、
以下の違いがありうるので、それぞれのデータセットのドキュメントを参考にしてください。
リスト6-1 データセット読み込みのソースコード(MNIST.py)
1 def dataset(MODEL):
2 # 前処理
3 if (MODEL == 0) or (MODEL == 1):
4 transform = transforms.Compose([
5 transforms.ToTensor(), # 必須
6 ])
7 else:
8 transform = transforms.Compose([
9 transforms.ToTensor(), # 必須
10 #transforms.Resize(56), # リサイズ(オプション)
11 ])
12
13 # データファイルを保存する場所
14 data_root = os.getcwd()
15
16 # 訓練、テスト用データセット(60000, 10000)
17 train_set = datasets.MNIST(root=data_root, train=True, download=True, transform=transform)
18 test_set = datasets.MNIST(root=data_root, train=False, download=True, transform=transform)
19
20
21 return train_set, test_set
図6-1にデータセットのうちのテストデータの各文字の最初の20個の画像を示します。
図6-2にネットワークのモデルを変えたときの正解率を示します。
正解率を上げるにはチャネル数を増やすより層数を増やすほうが効果があることがわかります。
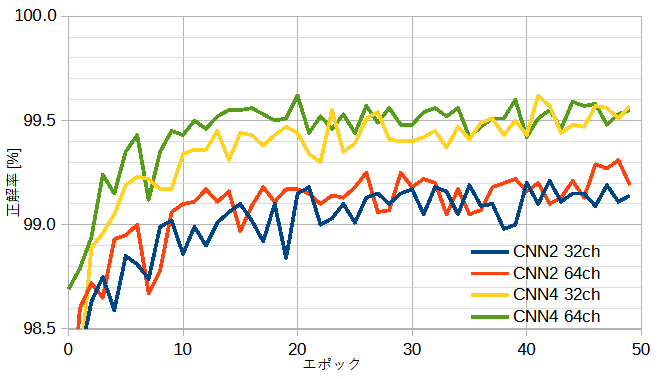
図6-3にドロップアウト有無のときの収束状況を示します。
ドロップアウトを加えることによって損失が減り正解率が上がることがわかります。
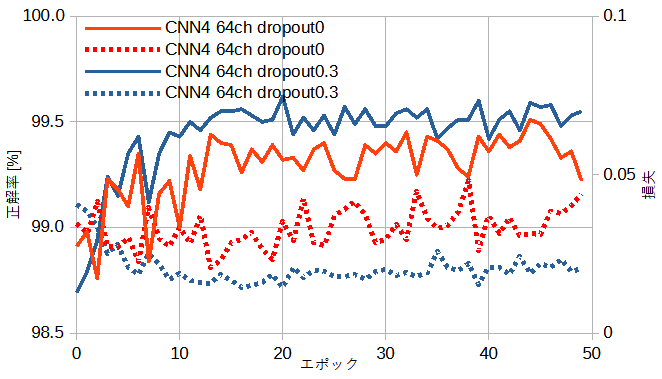
図6-4にネットワーク別の最高正解率を示します。
CNN4(32ch)ですでに正解率99.6%を超え、
パラメーターをそれ以上大きくしても正解率は上がりません。
この値は現在までに報告されている最高正解率99.87%に近いので、
MNISTに関してはCNN4程度のネットワークで十分と言えます。
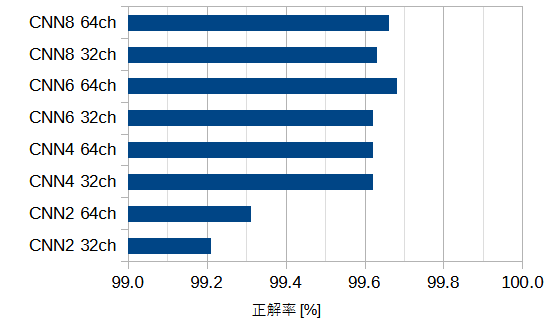
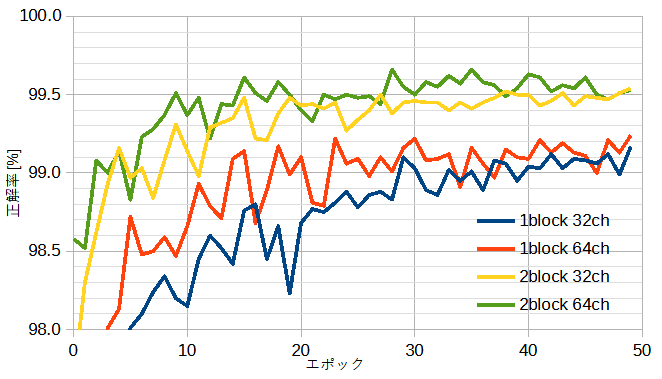
図6-5にネットワークのモデルを変えたときの正解率を示します。
自作CNNと同じく、正解率を上げるにはチャネル数を増やすよりブロック数を増やすほうが効果があることがわかります。
なお、nブロックは自作CNN2nと同じ層数に相当します。
最高の正解率は自作CNNとほぼ同じです。
公開ResNetは224x224ピクセルのImageNet向けに最適化されているので、
画像サイズが小さいデータセットに用いるには前処理としてリサイズを行うことが有効です。
したがってハイパーパラメーターとしてリサイズの大きさを持ちます。
図6-6にリサイズ28/56/112/224のときの正解率を示します。
重みなしのときはゼロからの学習となります。
リサイズを大きくすると正解率は上がりますが計算時間も増えます。
最高の正解率は自作CNNとほぼ同じです。
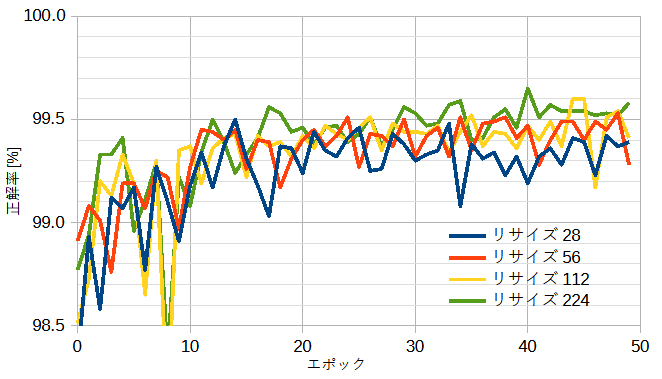
図6-6にリサイズ28/56/112/224のときの正解率を示します。
重みありのときは事前学習(最適化されたパラメーター)からのファインチューニングなので速やかに収束します。
重みなしと比べるとリサイズの効果が見られます。
最高の正解率は自作CNNとほぼ同じです。
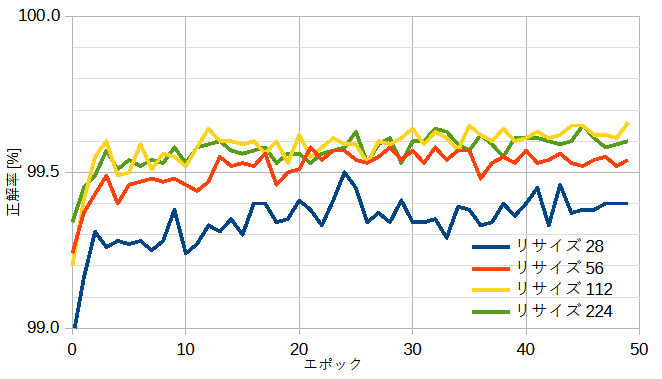
図6-8に不正解のすべてを示します。全10000個のうちの37個です。
画像の上に正解ラベルを示します。
不正解の時は赤字で上に正解、下に誤回答を示します。
