MNISTは正解率が99%以上と高く正解率に統計的な差がつきにくいので、
テストデータ数を10000から60000に増やしたものがQMNIST[15]です。
(訓練データ数は60000のまま)
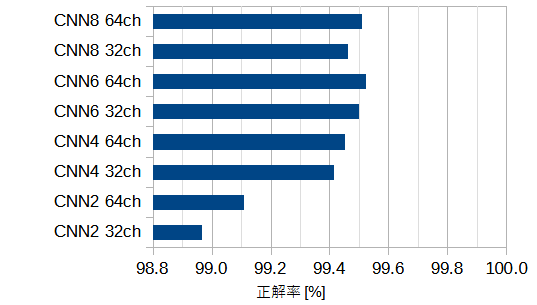
図7-1に自作CNNのモデルを変えたときの正解率を示します。
MNISTと同じ傾向ですが正解率は全体的に0.1%程度下がっています。
図7-2に自作ResNetと公開ResNetの正解率を示します。
正解率は、ResNet(重みなし)<自作ResNet<ResNet(重みあり)となります。
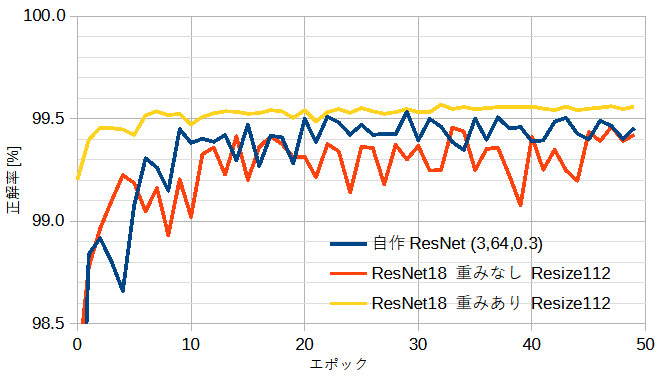
図7-3に不正解データの最初の200個を示します。
不正解の時は赤字で上に正解、下に誤回答を示します。

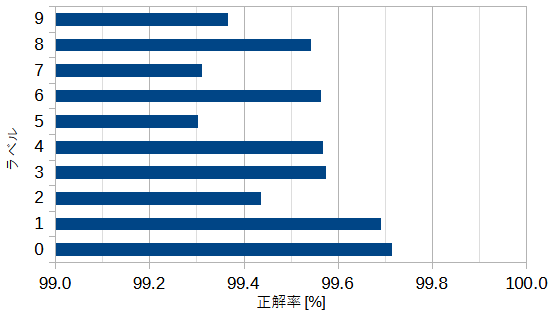
図7-4にラベル別の正解率を示します。