EMNIST[16]は手書きの英数字(0-9,A-Z,a-z)の画像のデータセットです。
ここでは文字ごとのデータ数が同じである"Balanced"データセットを使用します。
112800(=2400*47)個の訓練データと18800(=400*47)個のテストデータから成ります。
以下の15字は大文字と小文字の区別がつきにくいのですべて大文字と仮定しています。
c i j k l m o p s u v w x y z
したがって分類数は10+26+26-15=47です。
図8-1にデータセットのうちのテストデータの各文字の最初の20個の画像を示します。
図8-2にCNN6を一定とし、チャンネル数を変えたときの正解率を示します。
これから128chは64chより優れ、192chは128chとほぼ同じであることがわかります。
図8-3に128chを一定とし、CNN4~CNN8と変えたときの正解率を示します。
これからCNN6はCNN4より優れ、CNN8はCNN6とほぼ同じであることがわかります。
以上からEMNISTでは"CNN6 128ch"で十分であることがわかります。
正解率は最高90.52%です。
英数字では、0(ゼロ)とO(オー)など本質的に区別できない文字があるために、
これ以上の正解率は容易ではありません。
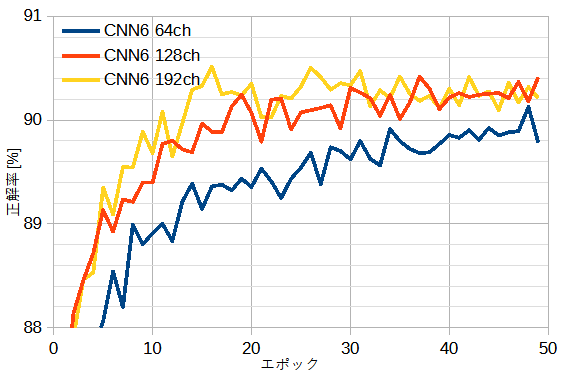
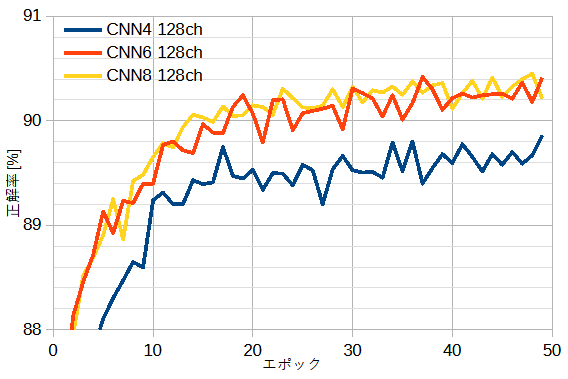
図8-4に自作ResNetのモデル(ブロック数, チャンネル数, ドロップアウト確率)
を変えたときの正解率と損失を示します。
ドロップアウト確率0.3でも過学習が見られ損失が反転し正解率が低下します。
ドロップアウト確率0.6にすると過学習が抑えられます。
正解率は最高90.69%となり自作CNNと同等です。
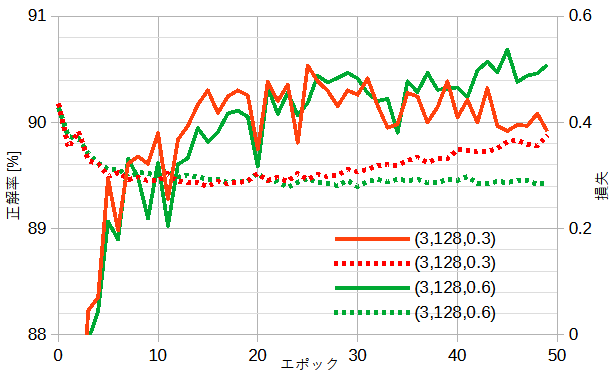
図8-5に公開ResNetの重みなしとありのときの正解率と損失を示します。
公開ResNetはドロップアウトを持たないために、
どちらのケースでも過学習が抑えらません。
公開ResNetはEMNISTには不向きと思われます。
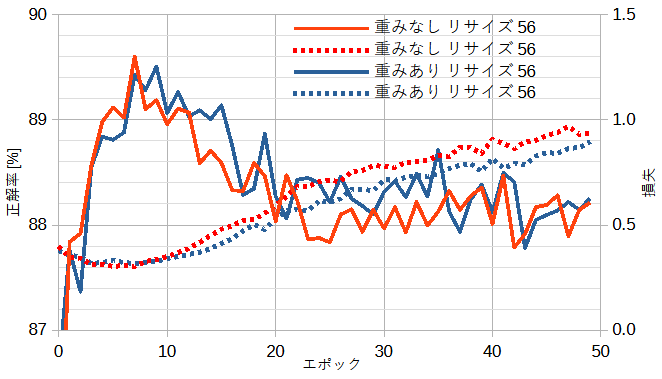
図8-6にテスト結果を示します。テストデータは最初の200個です。
上が正解、下が誤回答です。
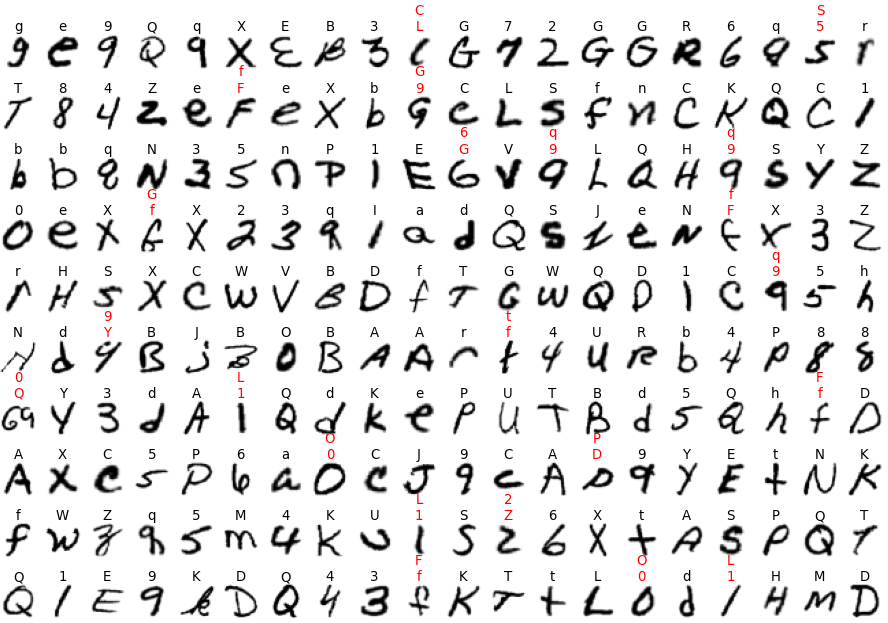
図8-7に不正解の最初の200個を示します。

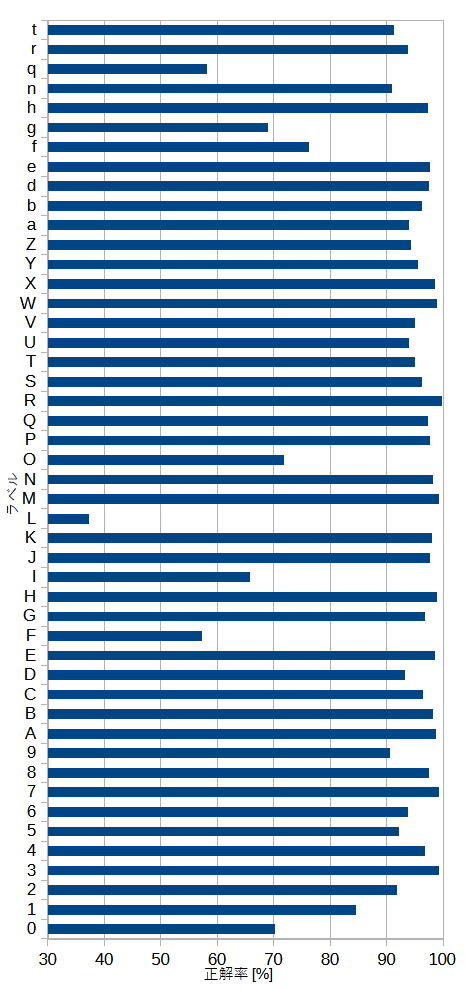
図8-8にラベル別の正解率を示します。
"L"の正解率が極端に低く、次に"qgfOIF0"の正解率が低いことがわかります。