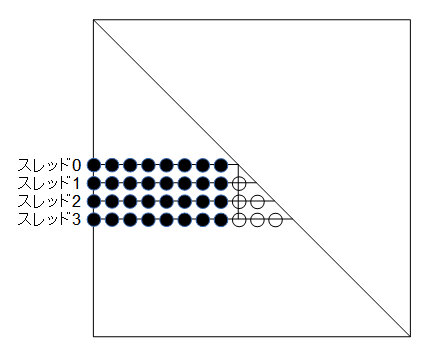
図3-2-1 コレスキー分解の並列計算(4スレッドの場合、●:並列計算、○:逐次計算)
OpenMOMの計算時間の大部分を占める式(2-6-5)の2番目のiループは、
図3-2-1に示される●部分を並列計算をすることができます。
一方、○部分は並列計算できませんのでスレッド0で逐次計算します。
ここでスレッド数をMとすると、並列部はMN個の演算をNの時間で計算し、
逐次部はM2/2個の演算をM2/2の時間で計算します。
従ってM<<√(2N)のとき逐次部の計算時間を無視することができ十分な並列性能が得られます。
この条件は例えばN=10000のときM<<140に相当します。
なお、式(2-6-7)の前進代入と後退代入は逐次計算ですので並列化できませんが、
この部分の計算時間はN2のオーダーですので全体の計算時間に与える影響は無視することができます。
図3-2-1 コレスキー分解の並列計算(4スレッドの場合、●:並列計算、○:逐次計算)
リスト3-2-1はコレスキー分解をOpenMPで並列化したソースコードです。
関数cholesky1_rowは式(2-6-5)のjループをjmin<=j<jmaxの範囲で計算するものであり、
これは並列計算と逐次計算で共通化できますので関数として取り出したものです。
この中の関数cdotは3.1で説明したものです。
OpenMPによる並列化とSIMDによるベクトル化は互いに独立ですので併用することができます。
46-56行がOpenMPの並列領域です。48行でスレッド番号を取得し、
52行で行番号iを設定しています。
なお、作業配列wは競合するためにスレッドごとに用意する必要があります。
M<<N なので必要メモリーの増加は無視することができます。
リスト3-2-1 OpenMPを用いたコレスキー分解の並列化(cholesky.c)
1 // single row
2 static void cholesky1_row(
3 int simd, int i, int jmin, int jmax,
4 float **a_r, float **a_i, f_complex_t *d, float *w_r, float *w_i)
5 {
6 float sum_r, sum_i;
7
8 for (int j = jmin; j < jmax; j++) {
9 cdot(simd, j, a_r[j], a_i[j], w_r, w_i, &sum_r, &sum_i);
10
11 w_r[j] = a_r[i][j] - sum_r;
12 w_i[j] = a_i[i][j] - sum_i;
13
14 float tmp = 1 / ((d[j].r * d[j].r) + (d[j].i * d[j].i));
15 a_r[i][j] = ((w_r[j] * d[j].r) + (w_i[j] * d[j].i)) * tmp;
16 a_i[i][j] = ((w_i[j] * d[j].r) - (w_r[j] * d[j].i)) * tmp;
17
18 d[i].r -= (w_r[j] * a_r[i][j]) - (w_i[j] * a_i[i][j]);
19 d[i].i -= (w_i[j] * a_r[i][j]) + (w_r[j] * a_i[i][j]);
20 }
21 }
22
23 // cholesky decomposition
24 static void cholesky1(
25 int nthread, int simd, int n,
26 float **a_r, float **a_i, f_complex_t *d, float **w_r, float **w_i)
27 {
28 for (int i = 0; i < n; i++) {
29 d[i].r = a_r[i][i];
30 d[i].i = a_i[i][i];
31 a_r[i][i] = a_i[i][i] = 0;
32 }
33
34 // number of blocks = n / nthread
35 int nblock = (n + (nthread - 1)) / nthread;
36
37 for (int iblock = 0; iblock < nblock; iblock++) {
38 // starting row number
39 int i0 = iblock * nthread;
40
41 // parallel part
42 if (nthread > 1) {
43 #ifdef _OPENMP
44 #pragma omp parallel
45 #endif
46 {
47 #ifdef _OPENMP
48 int tid = omp_get_thread_num();
49 #else
50 int tid = 0;
51 #endif
52 int i = i0 + tid;
53 if (i < n) {
54 cholesky1_row(simd, i, 0, i0, a_r, a_i, d, w_r[tid], w_i[tid]);
55 }
56 }
57 }
58
59 // serial part or single thread
60 for (int i = i0; (i < i0 + nthread) && (i < n); i++) {
61 int j0 = (nthread > 1) ? i0 : 0;
62 int tid = i - i0;
63 cholesky1_row(simd, i, j0, i, a_r, a_i, d, w_r[tid], w_i[tid]);
64 }
65 }
66 }
その他、以下の処理は計算時間に占める割合は小さいですが、
OpenMPの指示文を1行入れるだけで並列化できますのでOpenMPにより並列化しています。