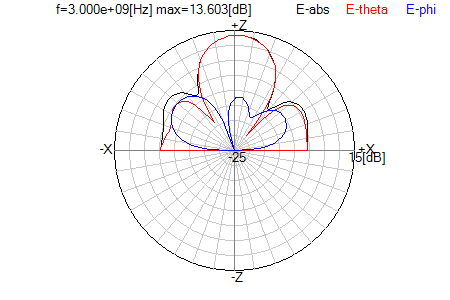
図8-1 遠方界面上図
OpenMOMを用いたアンテナの最適設計ツールです。
ソースコードは arm/ フォルダにあります。
Microsoft Visual Studio と Microsoft MPI がインストールされているものとします。
コマンドプロンプトでarmフォルダに移動した後、下記のコマンドを実行します。
> nmake.exe clean > nmake.exe(注):
コマンドプロンプトでarmフォルダに移動した後、下記のコマンドを実行します。
> ./arm.exe [nthread nrepeat nloop seed1 seed2] (1プロセスのとき) > mpiexec.exe -n <nprocess> ./arm.exe [nthread nrepeat nloop seed1 seed2] (マルチプロセスのとき)
ここで引数の意味は以下の通りです。
nthread : OpenMPで並列計算するスレッド数
nrepeat : 試行回数
nloop : 反復回数
seed1, seed2 : 乱数の種 = seed1 + (試行番号 * seed2)
nprosess : MPIのプロセス数
例えば以下のようになります。
> ./arm.exe (1プロセス、ソースコードに記入された引数を使用するとき) > ./arm.exe 8 32 3000 1000 500 (1プロセス、8コアのとき、8スレッド) > mpiexec.exe -n 8 ./arm.exe (8プロセス、ソースコードに記入された引数を使用するとき) > mpiexec.exe -n 8 ./arm.exe 1 32 3000 1000 500 (8プロセス、8コアのとき、各1スレッド) > mpiexec.exe -hosts 2 localhost 8 PC2 8 ./arm.exe 1 32 3000 1000 500 (8コア(自PC)+8コア(ホスト名:PC2)の2ノードのとき)・コア数が限られているときはMPIのプロセス数に配分したほうが計算時間が短くなります。
最初に計算モデルに合わせてソースコードを下記の例のように編集します。
Main.c
// frequency double freq0 = 3.0e9; 開始周波数 double freq1 = 3.0e9; 終了周波数 int freqdiv = 0; 周波数分割数getvalue.c
double f = 0; 目的関数値 // gain f -= gain(ifreq, theta, phi, pol, db); 利得 // input impedanece f += 0.03 * zindiff(ifeed, ifreq, z0); 入力インピーダンスその後、(1)に従ってコンパイルし、(2)に従って実行します。
> mpiexec.exe -n 8 ./arm.exe 1 32 3000 1000 500 ARM Version 4.2 nprocess=8 nthread=1 (SSE) プロセス数とスレッド数 (使用したSIMD) nrepeat=32 nloop=3000 seed(2)=1000,500 segment=220*2 nfrequency=1 試行回数、反復回数、乱数その他 0 1* -11.810552 (2891, 105) プロセス番号、試行番号、目的関数値最小値(そのときの反復番号とON線分数) 4 5* -11.806494 (1620, 108) 2 3* -10.526569 (2394, 115) 6 7* -13.021080 (2194, 124) 7 8* -11.798318 (2665, 121) 1 2* -12.006064 (1872, 118) 5 6* -13.424585 (2782, 123) 3 4* -12.411922 (2242, 126) 0 9 -11.723332 (2559, 118) 4 13* -12.456968 (2222, 120) 1 10* -12.218752 (2972, 117) 2 11* -12.315256 (2234, 120) 3 12* -12.418524 (1928, 110) 6 15 -10.712554 (1759, 119) 7 16* -12.846009 (2958, 130) 5 14 -11.574866 (1032, 126) 0 17* -12.172508 (1307, 115) 6 23 -11.268671 (1428, 97) 4 21 -11.359669 (1024, 115) 1 18 -11.571979 (2273, 123) 7 24 -12.778628 (1961, 104) 3 20 -12.372831 (1102, 116) 2 19 -10.858554 (2590, 126) 5 22 -13.007562 (1717, 117) 4 29 -11.846949 (1658, 105) 6 31 -12.672050 (2977, 115) 0 25* -13.375415 (1907, 119) 1 26 -11.937270 (2558, 115) 7 32 -12.699960 (2945, 114) 5 30 -12.918185 (2298, 111) 3 28* -13.119262 (2599, 130) 2 27 -11.548137 (1056, 122) fmin = -13.424585 目的関数最小値 output : arm.omm, arm.ofd 出力されたファイル cpu time = 134.377 [sec] 計算時間試行番号に*がついているものはそのプロセスで目的関数が最小を更新したことを表します。
出力されたarm.ommをOpenMOMで開いて計算すると、
図8-1のような図形出力が得られます。
図8-1 遠方界面上図