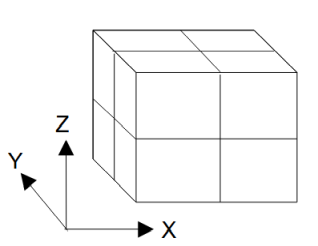
図3-3-1 計算領域のプロセスへの分割(X分割=2、Y分割=2、Z分割=2、プロセス数=8の場合)
MPIを用いて並列計算するには図3-3-1のように計算領域を分割します。
CPU版とGPU版の両方に適用することができます。
プロセス数をPとすると計算時間が1/Pになります。
電圧分布計算時の各プロセスの必要メモリーは1/Pですが、
計算結果をファイルに保存するときに、
CPUのルートプロセスが全領域の電圧を持ちます。
図3-3-1 計算領域のプロセスへの分割(X分割=2、Y分割=2、Z分割=2、プロセス数=8の場合)
2.1で述べたように差分法では隣の節点の電圧値を使用するので、
プロセスの境界面では隣のプロセスの電圧値が必要になります。
従って図3-3-2のようにMPIの通信によって送信と受信を行います。
通信は各反復計算ごとに必要になります。red-black法では反復計算ごとに2回必要になります。
X方向に分割するときの通信量は(Ny+1)*(Nz+1)ワードなので、
Nx/Pが十分大きければ通信に要する時間は無視することができます。
領域分割数については一般に、
X方向分割数 >= Y方向分割数 >= Z方向分割数
のとき効率よくなります。
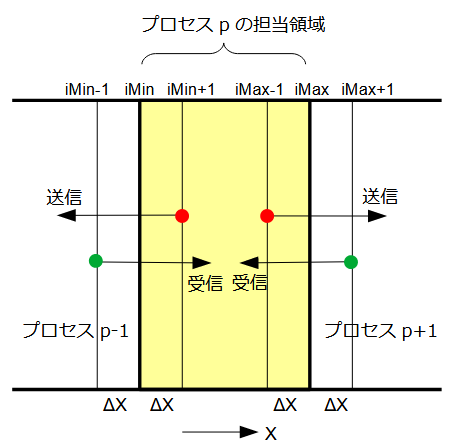
図3-3-2 隣接プロセスとの通信(X方向に分割したとき)
リスト3-3-1に通信部を示します。
送受信時にデッドロックが発生しないように設計されているMPI_Sendrecv関数を使用します。
-方向の境界面と+方向の境界面の2回必要になります。
リスト3-3-1 隣接プロセスとの送受信(comm_X.cの一部)
1 // V to buffer
2 static void v_to_buffer(int i, real_t v[], real_t buf[], int j0, int j1, int k0, int k1)
3 {
4 for (int j = j0; j <= j1; j++) {
5 for (int k = k0; k <= k1; k++) {
6 const int64_t m = (j - j0) * (k1 - k0 + 1) + (k - k0);
7 buf[m] = v[D(i, j, k)];
8 }
9 }
10 }
11
12 // buffer to V
13 static void buffer_to_v(int i, real_t v[], real_t buf[], int j0, int j1, int k0, int k1)
14 {
15 for (int j = j0; j <= j1; j++) {
16 for (int k = k0; k <= k1; k++) {
17 const int64_t m = (j - j0) * (k1 - k0 + 1) + (k - k0);
18 v[D(i, j, k)] = buf[m];
19 }
20 }
21 }
22
23 void comm_X(void)
24 {
25 #ifdef _MPI
26 MPI_Status status;
27 const int tag = 0;
28 int bx[] = {Ipx > 0, Ipx < Npx - 1};
29 int px[] = {Ipx - 1, Ipx + 1};
30 int isend[] = {iMin + 1, iMax - 1};
31 int irecv[] = {iMin - 1, iMax + 1};
32 int i;
33
34 for (int side = 0; side < 2; side++) {
35 if (bx[side]) {
36 // V to buffer
37 i = isend[side];
38 v_to_buffer(i, V, SendBuf_x, jMin, jMax, kMin, kMax);
39
40 // MPI
41 const int ipx = px[side];
42 const int dst = (ipx * Npy * Npz) + (Ipy * Npz) + Ipz;
43 const int count = (jMax - jMin + 1) * (kMax - kMin + 1);
44 MPI_Sendrecv(SendBuf_x, count, MPI_REAL_T, dst, tag,
45 RecvBuf_x, count, MPI_REAL_T, dst, tag, MPI_COMM_WORLD, &status);
46
47 // buffer to V
48 i = irecv[side];
49 buffer_to_v(i, V, RecvBuf_x, jMin, jMax, kMin, kMax);
50 }
51 }
52 #endif
53 }
表3-3-1にMPIの計算時間を示します。
計算時間はOpenMP(表3-2-1)と同じ傾向を示します。
OpenMPと同じくMPIでも、使用メモリーが少ないnovectorモードを推奨します。
また、ハイパースレッディングの効果はないのでプロセス数には物理コア数を推奨します。
| プロセス数 | novector | vector |
|---|---|---|
| 1 | 74.4秒 (1.0) | 68.3秒 (1.0) |
| 2 | 39.7秒 (1.9) | 34.7秒 (2.0) |
| 4 | 19.8秒 (3.8) | 18.0秒 (3.8) |
| 8 | 13.8秒 (5.4) | 14.9秒 (4.6) |
| 16 | 17.3秒 (4.3) | 21.1秒 (3.2) |
表3-3-2に各ベンチマークの計算時間を示します。
| ベンチマーク | novector | vector |
|---|---|---|
| 300 | 13.8秒 | 14.9秒 |
| 400 | 31.5秒 | 42.8秒 |
| 500 | 63.7秒 | 83.9秒 |
| 600 | 109.8秒 | 153.1秒 |