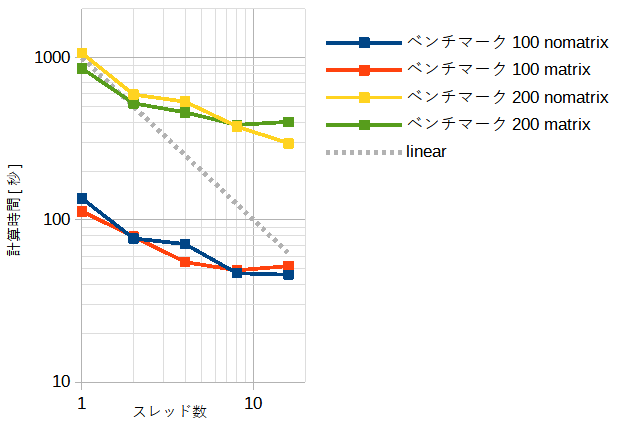
図3-3-1 OpenMPの計算時間(CPU)
OpenMPでは並列化可能なループの直前に指示文を記入します。
図2-9-2の行列・ベクトル積はデータ依存関係がないので、
一番外側のループをOpenMPを用いてそのまま並列化することができます。
ベクトル同士の演算(BLAS Level-1)も以下のように簡単に並列化することができます。
リスト3-3-1 OpenMPによるコピー(Zcopy)の並列化
void Zcopy(int64_t n, const d_complex_t *x, d_complex_t *y)
{
int64_t i;
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (i = 0; i < n; i++) {
y[i].r = x[i].r;
y[i].i = x[i].i;
}
}
リスト3-3-2 OpenMPによる内積(Zdotu)の並列化
d_complex_t Zdotu(int64_t n, const d_complex_t *x, const d_complex_t *y)
{
d_complex_t ret;
double sum_r = 0, sum_i = 0;
int64_t i;
#ifdef _OPENMP
#pragma omp parallel for reduction (+:sum_r, sum_i)
#endif
for (i = 0; i < n; i++) {
sum_r += (x[i].r * y[i].r) - (x[i].i * y[i].i);
sum_i += (x[i].r * y[i].i) + (x[i].i * y[i].r);
}
ret.r = sum_r;
ret.i = sum_i;
return ret;
}
表3-3-1と図3-3-1にスレッド数と計算時間の関係を示します。
スレッド数が少ないときはmatrixモードの方が速いですが、
スレッド数が多いときはnomatrixモードの方が速くなります。
多スレッドでは両者の差は小さいので使用メモリーの少ないnomatrixモードを推奨します。
またスレッド数は物理コア数(=8)と論理コア数(=16)の差は小さいのでどちらでもかまいません。
| スレッド数 | benchmark100 | benchmark200 | ||
|---|---|---|---|---|
| nomatrix | matrix | nomatrix | matrix | |
| 1 | 142秒 (1.0) | 91秒 (1.0) | 1121秒 (1.0) | 729秒 (1.0) |
| 2 | 81秒 (1.8) | 55秒 (1.7) | 640秒 (1.8) | 463秒 (1.6) |
| 4 | 49秒 (2.9) | 39秒 (2.3) | 397秒 (2.8) | 309秒 (2.4) |
| 8 | 36秒 (3.9) | 35秒 (2.6) | 277秒 (4.0) | 273秒 (2.7) |
| 16 | 33秒 (4.3) | 38秒 (2.4) | 242秒 (4.6) | 295秒 (2.5) |
図3-3-1 OpenMPの計算時間(CPU)