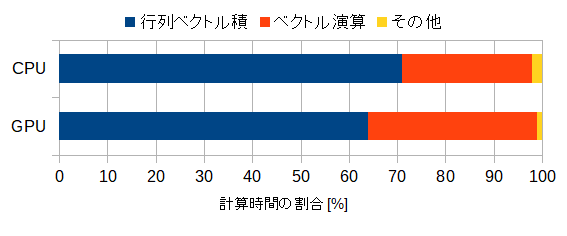
(a) matrixモード
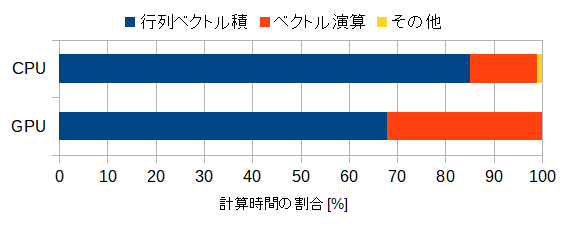
(b) nomatrixモード
図3-7-1 計算時間の内訳
表3-7-1に各手法の計算時間をまとめます。
ハードウェアの詳細は3.2の通りです。
CPUではOpenMPまたはMPIによる並列化で約3~4倍速くなります。
GPUではそれよりさらに約4~5倍速くなります。
CPU、GPUともに使用メモリーの少ないnomatrixモードを推奨します。
| ハードウェア | 高速化手法 | 計算時間 | 出所 | |
|---|---|---|---|---|
| nomatrix | matrix | |||
| CPU | (参考)並列化なし | 1121秒 | 729秒 | 表3-3-1 |
| CPU | OpenMP 8スレッド | 277秒 | 273秒 | 表3-3-1 |
| CPU | MPI 8プロセス | 319秒 | 286秒 | 表3-4-1 |
| GPU | CUDA | 61秒 | メモリー不足 | 表3-6-1 |
| GPU(H100) | CUDA | 10秒 | 10秒 | 新規 |
計算時間の内訳は図3-7-1の通りです。
CPUではnomatrixモードでは行列ベクトル積の時間が増えるのでその比率が上がります。
GPUではその比率はあまり上がりません。
なお、ベクトル演算の計算時間はmatrixモードとnomatrixモードで同じです。
(a) matrixモード
(b) nomatrixモード
図3-7-1 計算時間の内訳