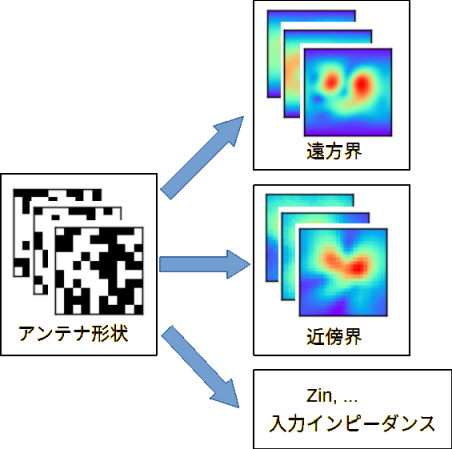
● データセット
ランダムにとった多数のアンテナ形状をモーメント法またはFDTD法で計算することによって、
図3-1のように、遠方界、近傍界、入力インピーダンスの3つのアンテナ特性が得られます。
これらの集合をデータセットと呼びます。
なお、本章の計算計算はモーメント法によるものですが、FDTD法でもほぼ同じです。
● アンテナ形状
図3-2にアンテナ形状の一例を示します。
上の数字はデータ番号とアンテナセル数です。
アンテナセル確率が0.5なのでアンテナセル数は平均的に10x10x0.5=50個あります。
なお、アンテナ形状の組み合わせ数は2100≈1030です。

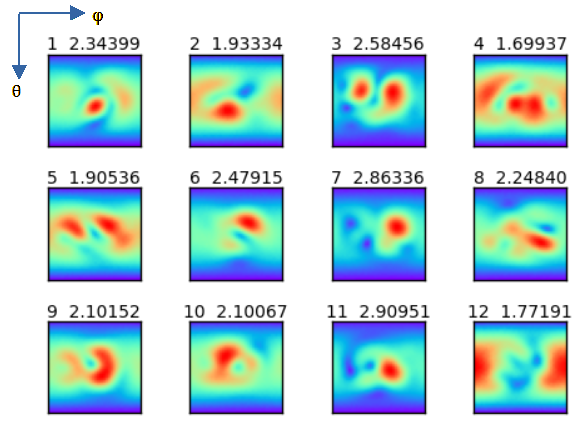
● 遠方界
図3-3に遠方界の一例を示します。
図中の値は sinθ√(|Eθ|2+|Eφ|2) です。
上の数字はデータ番号と最大値です。
遠方界については学習時の損失を考慮して立体角sinθをかけています。
したがって上辺と下辺では0となります。
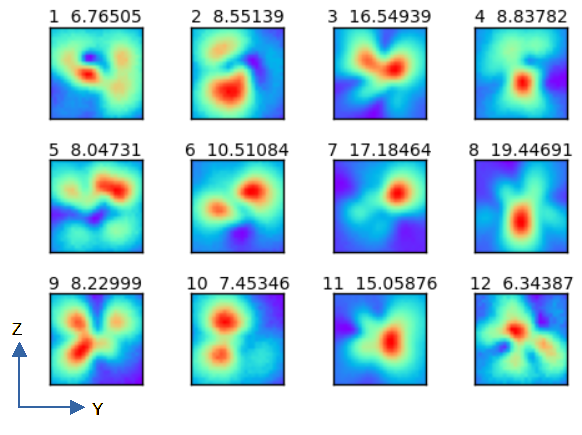
● 近傍界
図3-4に近傍界の一例を示します。
図中の値は √(|E|2+|ηH|2) です。
上の数字はデータ番号と最大値です。
近傍界については学習時に電界と磁界のオーダーを同じにするために、
磁界に真空の波動インピーダンスη(=120πΩ)をかけています。
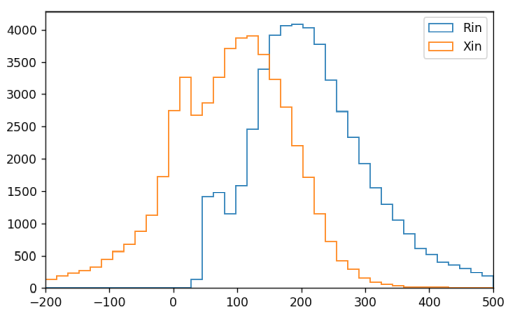
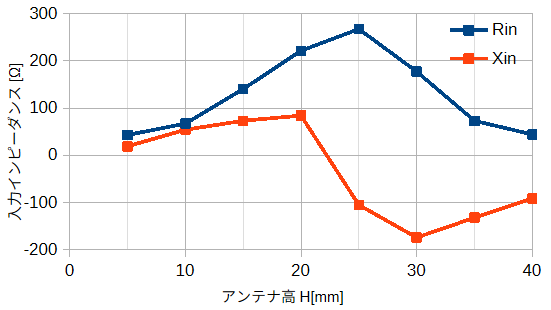
● 入力インピーダンス
図3-5に入力インピーダンスの頻度分布、
図3-6に入力インピーダンス平均とアンテナ高の関係を示します。
入力インピーダンスはアンテナ高Hと線分の半径rに依存します。
アンテナ高がλ/4に近いときに入力インピーダンスは純抵抗になりやすい傾向があります。
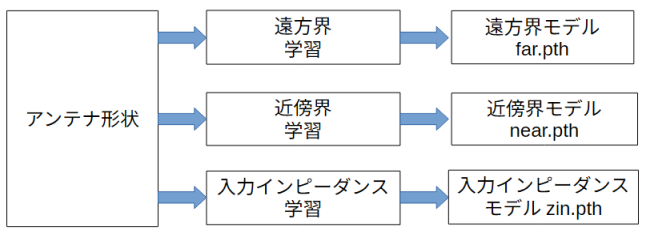
深層学習には画像認識に適しているCNN(畳み込みニューラルネットワーク)を使用します。
ニューラルネットワークとして軽量で精度のよいResNetを用います。
図3-7のように同じアンテナ形状から遠方界、近傍界、入力インピーダンスの三つを別々に学習します。
損失関数はそれぞれ式(3-1),(3-2),(3-3)とします。
ここで式(3-1)のEは複素数スカラー、式(3-2)のEとHは複素数ベクトル、
式(3-3)のZinは複素数スカラーです。
したがって成分数はそれぞれ4,12,2となります。
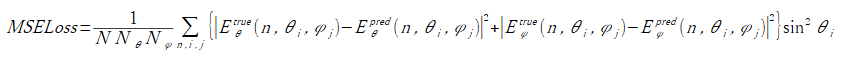 (3-1)
(3-1)
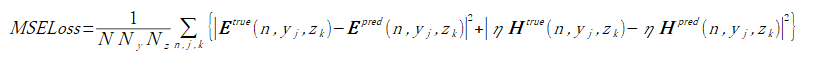 (3-2)
(3-2)
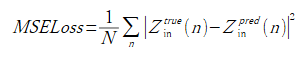 (3-3)
(3-3)
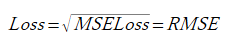 (3-4)
(3-4)
ニューラルネットワークの入力はアンテナ形状であり、
図3-2のような白黒2値ですがこれを0-1の実数に変換します。
さらに前処理として画素数の拡大(resize)を行うとモデルの性能が上がることが知られています。
図3-8はResNet18/34/50においてresizeの大きさを変えたときの遠方界損失の収束状況です。
図からResNet34のresize112/224のときに損失が最小になることがわかります。
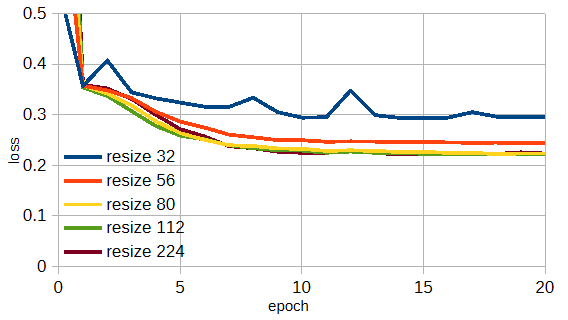
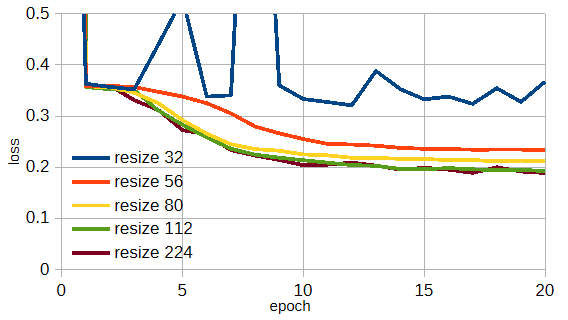
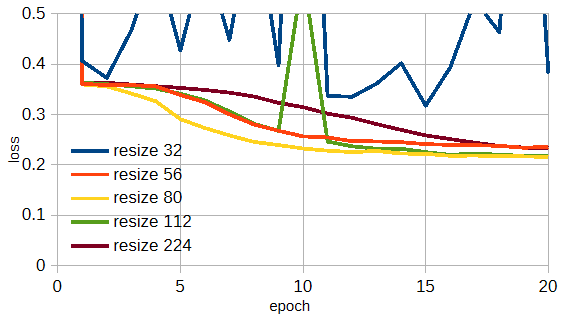
図3-8 モデルごとのresizeの効果(遠方界, データ数=20,000)
図3-9にモデルとresizeと計算時間の関係を示します。
これからネットワークの層数が増えたり、
resizeが大きくなると計算時間が増えることがわかります。
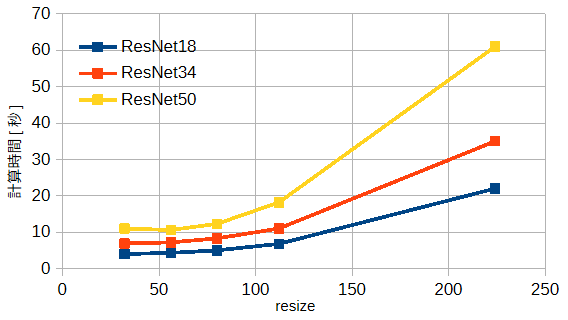
図3-10にモデルとresizeと使用メモリーの関係を示します。
計算時間と同様の傾向があります。
なおミニバッチを使用しているために、使用メモリーはデータ数と無関係です。
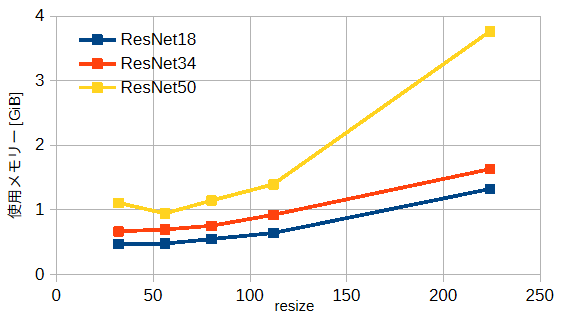
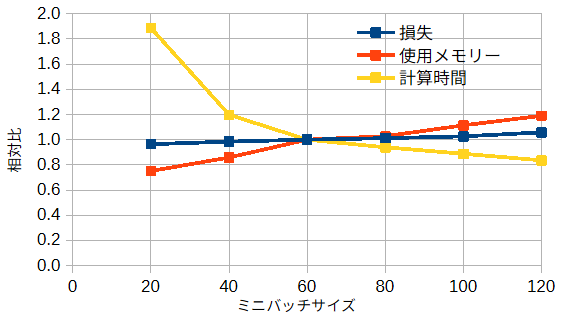
図3-11にミニバッチサイズと損失、使用メモリー、計算時間の関係を示します。
ミニバッチサイズ=60との相対比を示しています。
図からミニバッチサイズが大きくなると、使用メモリーが増え、
計算時間が短くなることがわかります。
損失はミニバッチサイズにあまり依存しません。
以上からミニバッチサイズ=60を採用します。
学習データの内訳とそのデータ数は以下の通りです。
(N:データ数, Nf:周波数数)
遠方界はEθ,Eφの複素数2成分、
近傍界はEx,Ey,Ez,Hx,Hy,Hzの複素数6成分です。
学習データの大部分は遠方界と近傍界が占めます。
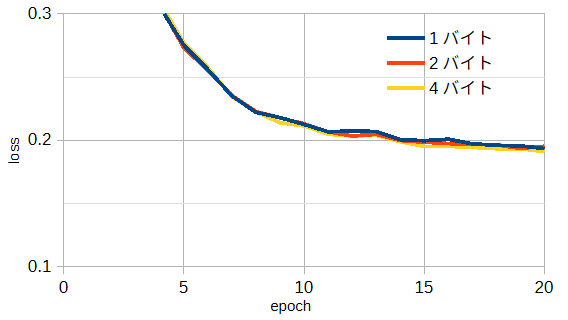
バイト数を減らしてファイルサイズを小さくすることができます。
図3-12はバイト数を変えたときの遠方界の損失です。
これからバイト数による影響は小さいと言えます。
以上から遠方界と近傍界のバイト数は1とします。
なお、アンテナ形状は1バイト、入力インピーダンスは4バイトとします。
データ数が少ないときは、訓練データに対する損失は下がっても、
テストデータに対する損失は下がりません。これを過学習(overfitting)と呼びます。
図3-13にデータ数と過学習の関係を示します。
図中で"データ数10000"は訓練データ数10000のときの訓練データに対する損失(訓練損失、破線)であり、
"データ数10000テスト"は訓練データ数10000のときのテストデータに対する損失(テスト損失、実線)です。
ここで、テストデータは訓練データとは異なる乱数の種で作成した一つのデータセットであり、
そのデータ数は2000です。
深層学習ではテスト損失が小さいことが要求されます(汎化性能)。
図から、訓練損失はデータ数が少ないときも小さくなり、
データ数による違いは大きくありません。これは過学習を示唆します。
一方、テスト損失は訓練損失より大きく、
かつデータ数が増えると小さくなり訓練損失に近くなります。
以上から、訓練データ数は可能な限り大きい方が望ましいことがわかります。
本ページでは特に断らないときの"損失"はテスト損失を意味します。
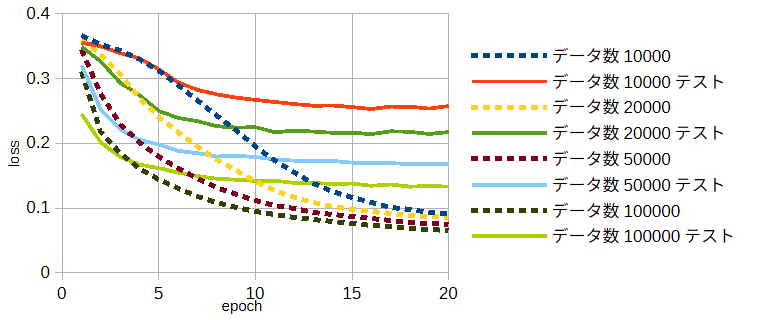
表3-1にモデルごとのパラメーター数を示します。
パラメーター数は、データ数、resize、ミニバッチサイズに依存しません。
| モデル | パラメーター数 |
|---|---|
| ResNet18 | 14,453,440 |
| ResNet34 | 24,561,600 |
| ResNet50 | 36,615,360 |
以上から、計算精度、計算時間、使用メモリーを考慮して深層学習の条件は表3-2とします。
| 条件 | 値 |
|---|---|
| モデル | ResNet34 |
| resize | 112 |
| 損失関数 | MSELoss |
| 最適化関数 | Adam |
| エポック数 | 20 |
| ミニバッチサイズ | 60 |
| ラベルバイト数 | 1 |