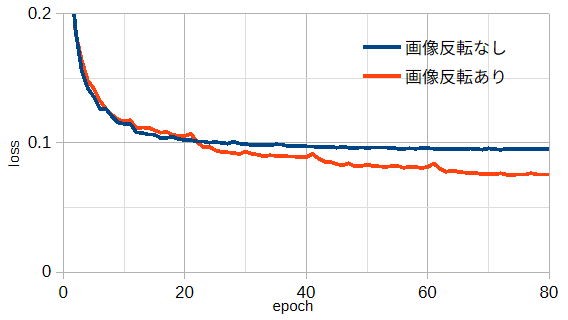
図4-1にデータ数を変えたときの、遠方界、近傍界、入力インピーダンスの損失を示します。
メモリー容量の関係から、データ数200,000以上は200,000ずつ分割して学習しています。
また、近傍界は給電電圧に比例するために、
遠方界(無次元)と同じオーダーになるように因子をかけています。
図から、遠方界と近傍界は同じ傾向があり、データ数が大きくなると損失が小さくなり、
推定精度が上がることがわかります。
入力インピーダンスについても減少度は小さいですが同様の傾向があります。
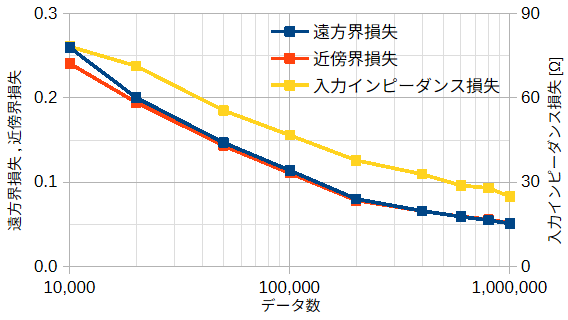
図4-2に12例の遠方界の推定結果を示します。上は正解で下は推定です。
上の黒数字はデータ番号と平均値、下の赤数字はデータ番号と誤差(L1誤差)です。
いずれも正しく推定できていることがわかります。
誤差の平均は0.029となり、これから遠方界を3%の誤差で推定できるがわかります。
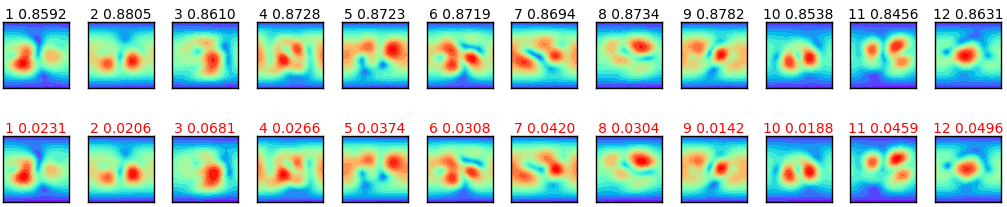
図4-3に12例の近傍界の推定結果を示します。上は正解で下は推定です。
いずれも正しく推定できていることがわかります。
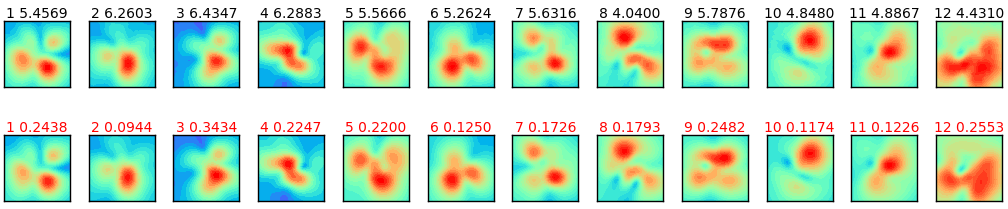
図4-4にデータ数を変えたときの、遠方界、近傍界、入力インピーダンスの損失を示します。
データ数100,000以上では、次節で説明するdata augmentation(データ増量)を使用しています。
図から、モーメント法と同じく、データ数が大きくなると損失が小さくなり、
推定精度が上がることがわかります。
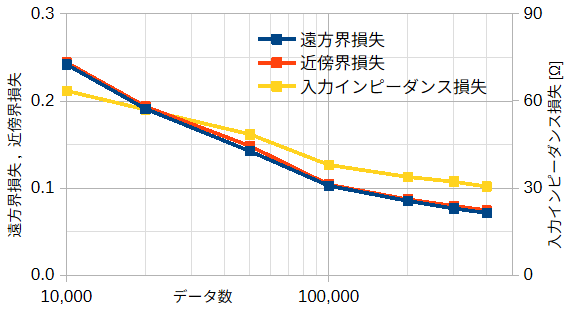
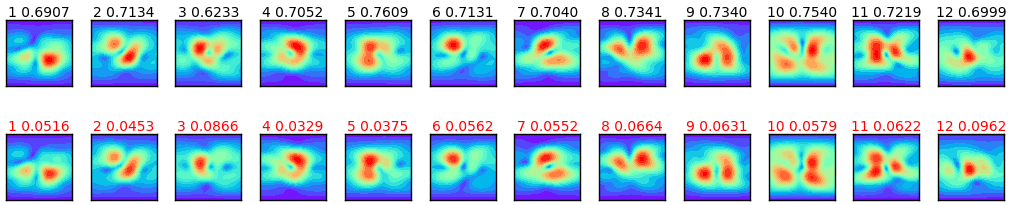
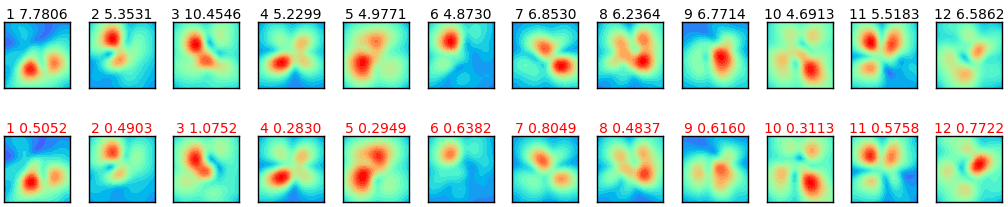
図4-5、図4-6に遠方界と近傍界の推定結果を示します。上は正解で下は推定です。
モーメント法と比べてデータ数が少ないので推定精度はやや落ちますが、
おおむね正しく推定できていることがわかります。
限られたデータから、画像を加工することによりデータ数を増やすことができます。
これをdata augmentation(データ増量)と呼びます。
本ケースでは給電点が中心にあることを利用して、
アンテナ形状と遠方界、近傍界を上下、左右、上下左右に反転することができます。
図4-7の青線は元データをそのままに80エポック計算したものです。
赤線は、20エポックごとに上下、左右、上下左右に反転したものです。
これから、データ増量はデータが実際に増えたことに近い効果があることがわかります。