古文書解読プログラムmojilaを起動するには、
エクスプローラーでmojila.exeをダブルクリックしてください。
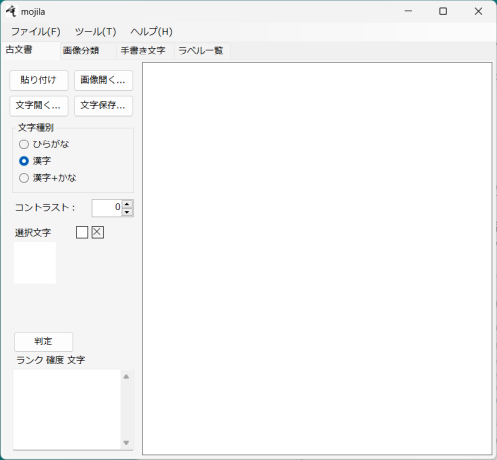
図3-1のウィンドウが現れます。
[古文書]、[画像分類]、[手書き文字]、[ラベル一覧]の4個のタブから成ります。
使い方については[ヘルプ]→[使い方]メニューも参考にしてください。
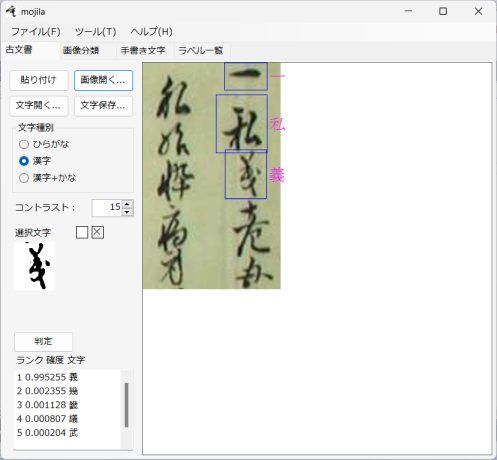
古文書の画像を読み込んで、一文字ずつ解読します。
画像の読み込み
[貼り付け]: クリップボード内の画像を貼り付けます。
[画像開く]: 画像ファイル(pngまたはjpg)を開きます。
文字データの保存
読み取った文字データを保存します。ファイルの拡張子はmojです。
画像ファイルと同じファイル名にすると便利です。
文字種別
[ひらがな]、[漢字]、[漢字+かな]から選択してください。
文字の選択
右のウィンドウ内で、判定したい文字を囲む領域をドラッグしてください。
以下の作業が自動的に行われます。
文字画像の編集
判定結果が思わしくないときは[選択文字]画像を編集してください。
[コントラスト]を変えると濃淡が変わります。
[選択文字]画像内をクリックするとその部分が白くなります。繰り返し行えます。
□をクリックすると黒地モードに変更されます。(トグルボタン)
×をクリックすると編集内容が初期化されます。
画像を修正すると自動的に再判定されます。
(注意)
[コントラスト]を0にすると無修正の画像になります。
[漢字]は修正された画像(背景が白色)で学習しているので[コントラスト]を適当に設定すると精度が上がります。
[漢字+かな]は無修正画像(背景が灰色)が多いデータで学習しているので無修正の方が精度が高くなることがあります。
文字の削除
右のウィンドウ内の矩形内を右クリックして[削除]をクリックすると
その文字の選択が解除されます。これによって矩形を選択し直すことができます。
文字コードとプロセス再起動
文字コードについてはPythonはUTF-8、C#はUTF-16であるために、
判定した文字列の一部が正しく変換されずにエラーメッセージが返ってくることがあります。
そのときは判定結果が空白になり、Pythonプログラムが再起動されます。
[ツール]→[設定]で[表示候補数]を小さくして再度[判定]するか、別の文字を選択してください。
クリップボードへの保存法(Windowsの機能)
Windowsの画面の任意の場所をクリップボードに保存するには、
キーボードで[Windows]+[shift]+[s]を同時に押すと画面が暗くなります。
ここで任意の矩形をドラッグします。
入力された画像を分類します。
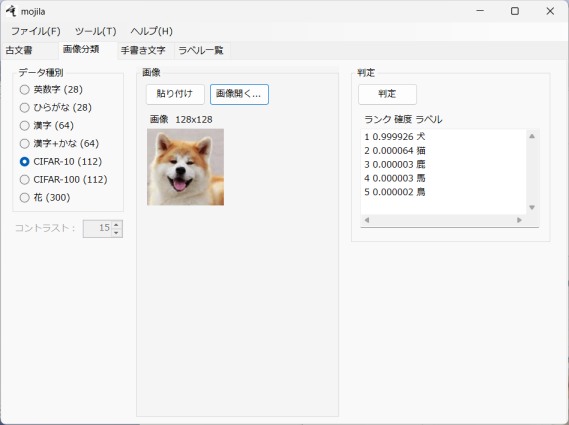
データ種別
データの種別を選択してください。
それぞれの内容は[1]を参考にしてください。
()内の数字は学習時の画像サイズ(ピクセル、正方形)であり、
入力された画像はこの大きさに変更されたのち判定されます。
したがって必要以上に大きな画像を入力しても判定結果は変わりません。
画像の読み込み
[貼り付け]: クリップボード内の画像を貼り付けます。
[画像開く]: 画像ファイル(pngまたはjpg)を開きます。
判定
画像を読み込んだら自動的に画像が分類されてその結果が下に表示されます。
確度(0~1)が高い順に並べられます。確度の合計は1です。
画像の編集
[データ種別]が[英数字]、[ひらがな]、[漢字]、[漢字+かな]のときは白黒の文字であり、
元画像の下に変換された画像が表示されます。
これが判定に使用される画像です。
判定結果が思わしくないときは下の画像を編集してください。
[コントラスト]を変えると濃淡が変わります。
下の画像内をクリックするとその部分が白くなります。繰り返し行えます。
□をクリックすると黒地モードに変更されます。(トグルボタン)
×をクリックすると編集内容が初期化されます。
画像を修正すると自動的に再判定されます。
手書き入力された文字を分類します。
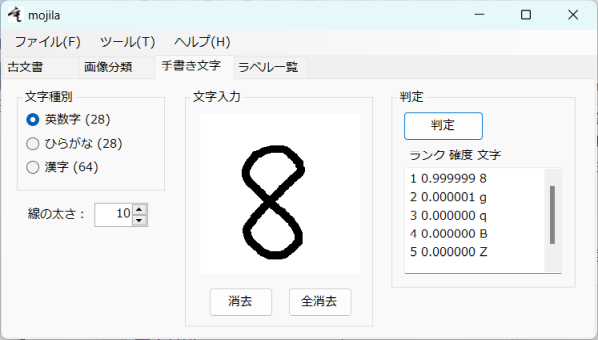
文字種別
入力する文字の種別を選択してください。
文字入力
ウィンドウ上でマウスをドラッグして文字を入力してください。
線の太さは[線の太さ]で変更できます。
判定
[判定]をクリックすると文字が分類されてその結果が下に表示されます。
確度(0~1)が高い順に並べられます。確度の合計は1です。
消去
[消去]をクリックすると最後の線分が消去されます。
[全消去]をクリックすると全部の線分が消去されます。
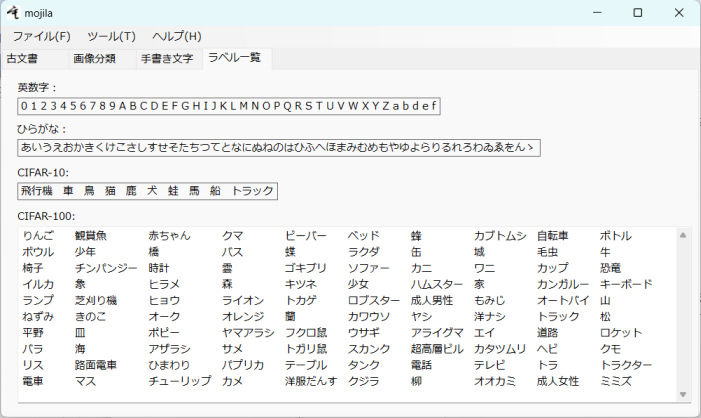
各データセットのラベル(画像の内容を表す名前)が表示されます。
詳細については[1]を参考にしてください。
この中にない画像を入力すると当然間違った答えが返ってきます。
(例えばCIFAR-10のときりんごの絵を入力するなど)
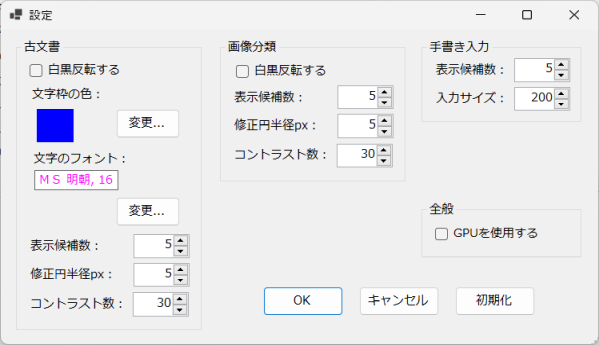
[ツール]→[設定]メニューをクリックすると図3-6の設定ウィンドウが現れます。
通常は既定値で十分です。
各データ種別のニューラルネットワークの仕様は表3-1の通りです。
| No. | データ種別 | ニューラルネットワーク | 前処理 | パラメーターファイル名 |
|---|---|---|---|---|
| 1 | 英数字 | CNN6 128ch | なし | _EMNIST.pth |
| 2 | ひらがな | CNN8 128ch | なし | _K49.pth |
| 3 | 漢字 | CNN10 192ch | なし | _KKanji.pth |
| 4 | 漢字+かな | CNN10 256ch | Resize(64) | _TKanji.pth |
| 5 | CIFAR-10 | ResNet50 (重みあり) | Resize(112), 正規化 | _CIFAR10.pth |
| 6 | CIFAR-100 | ResNet50 (重みあり) | Resize(112), 正規化 | _CIFAR100.pth |
| 7 | 花 | ResNet18 (重みあり) | Resize(300) | _Flowers102.pth |