

図4-1、図4-2にひらがな主体の文書例を示します。
選択した矩形の右に判定された文字が表示されます。
ひらがなは文字数が少ないために比較的正しく読むことができます。

図4-3~図4-7に漢字主体の文書例を示します。右に翻刻文をつけています。
誤回答に赤丸をつけています。




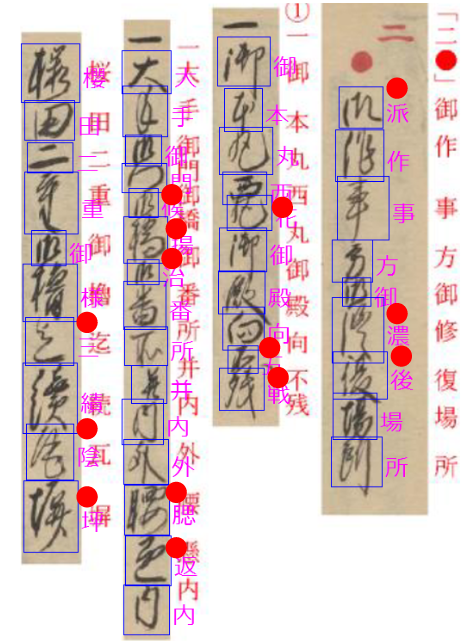
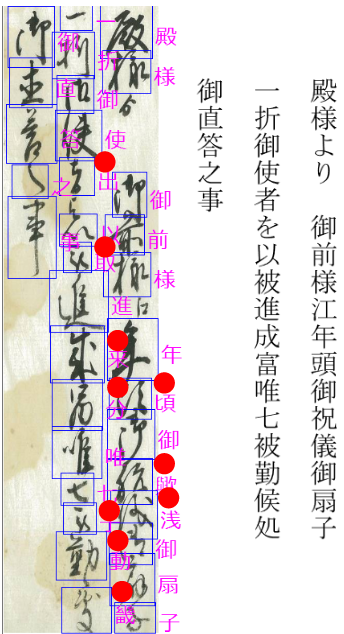
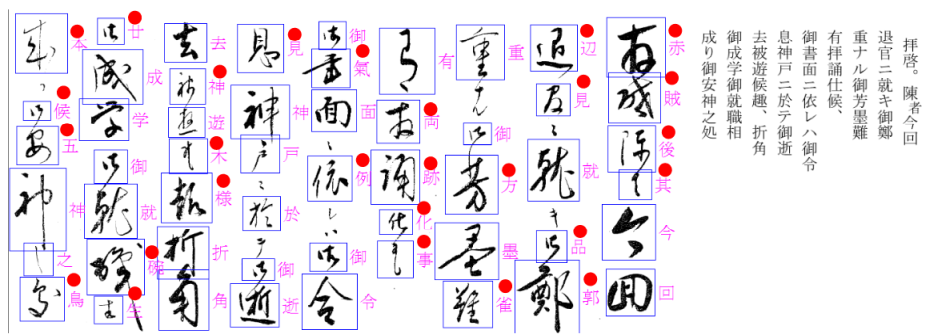

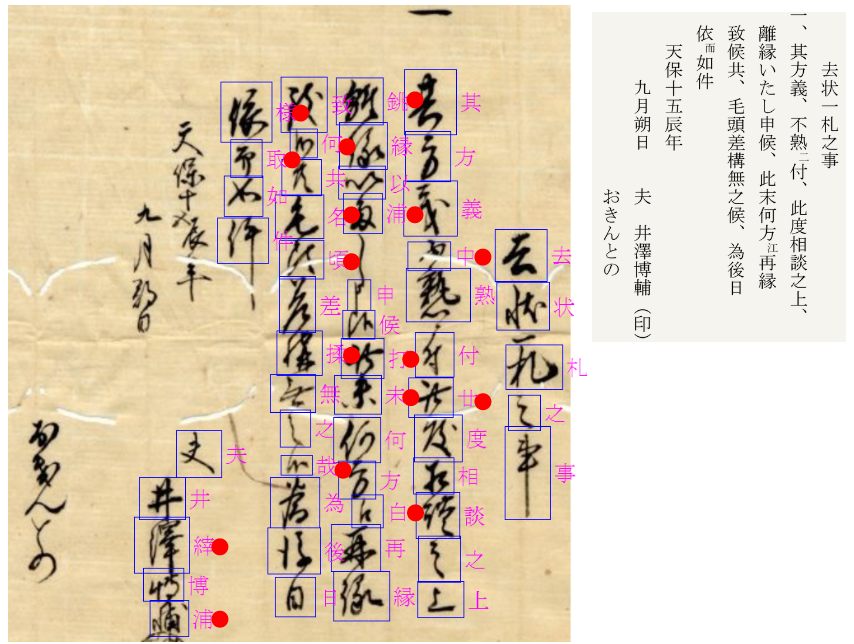
文字を選択しただけで正しく判定されることもありますが、
判定結果が正しくないと思われるときは、
以下のように選択画像を修正してください。
(1) コントラスト
コントラストの数字を閾値として白黒2値画像に変換されます。
コントラストが大きいときは太めの文字に、小さいときは細めの文字に変換されます。
したがって、墨が濃いときはコントラストは小さめに、
墨が薄いときはコントラストは大きめにとったほうが判定精度が上がります。
通常は、線の太さは人間にも判別しやすいほうがよいですが、
場合によってはつぶれた太い線やかすれた細い線のほうが判定精度が上がることがあります。
(要は、他の文字の確度を落とせばよいため)
特殊なケースとして、コントラストを0にすると階調を変えずに白黒反転されますが、
判定精度は悪いです。
(2) 矩形の選択
矩形の大きさは、文字全体を囲む最小限にしてください。
正方形に近いほうが望ましいです。
矩形が小さすぎて文字の判別に欠かせない線や点が不足していると判定精度が下がります。
矩形を変えるには、矩形内を右クリック+削除してから再度選択してください。
(3) 続き字の処理
くずし字は多くの場合前後の文字とつながっていますが、
これらは本来の文字ではないので判定精度が下がることがあります。
続き字部分をクリックして白くしてください。
矩形内に前後左右の文字の一部が入っている場合も同じです。
(4) シミ取り
元画像の黒いシミは誤判定の原因になります。シミをクリックして白くしてください。
(5) 虫食い
虫食い部分を補修するには、
□ボタンをクリックして■ボタンにして虫食い部分をクリックしてください。
筆の太さは[ツール][設定]メニューの[修正円半径]で変更することができます。
本プログラムの判定精度をさらに上げるには以下のような課題が考えられます。
(1) 文字のクリーニングの自動化
クリーニング作業を自動化して手作業による画像修正の手間を減らす。
(2) 学習の改良
学習時の前処理(data augmentationなど)を改良して正解率を上げる。
(3) 学習データの追加
漢字の学習データを増やす。
(4) 学習文字を絞る
学習時の文字を頻度の高い文字に絞ると、学習対象の文字の正解率が上がる可能性がある。
学習対象外の文字は読めない。