マルチスレッドとは、複数のコアを持ったCPUで、
同時に複数のスレッドを実行して処理を分割し計算時間を短縮するものです。
1台のコンピュータに複数のCPUが搭載されていればさらにその個数だけ速くなります。
スレッド関係の関数はVC++とgccで異なります。
VC++ではWindows独自の関数を呼び出し、
gccではPOSIX(Portable Operating System Interface for UNIX)準拠の関数を呼び出します。
スレッドの起動と終了
VC++ではCreateThread関数、gccではpthread_create関数でスレッドを起動し、
VC++ではWaitForMultipleObjects関数、gccではpthread_join関数でスレッドの終了を待ちます。
スレッド関数の引数
スレッド関数の引数は"void *"の一つだけなので、
複数の変数を渡すには構造体を作ってその中に格納します。
構造体のメンバーの数が多いときはグローバル変数にした方が便利なこともあります。
リスト6-1にベクトル内積をマルチスレッドで計算するプログラムを示します。
リスト6-1 マルチスレッドプログラム(thread_sdot.c)
1 /*
2 thread_sdot.c (thread)
3
4 VC++ : cl.exe /O2 thread_sdot.c
5 gcc : gcc -O2 thread_sdot.c -o thread_sdot [-lpthread] [-lm]
6
7 Usage :
8 > thread_sdot <num> <loop> <thread>
9 */
10
11 #include <stdlib.h>
12 #include <stdio.h>
13 #include <math.h>
14 #include <time.h>
15
16 #ifdef _WIN32
17 #include <windows.h>
18 HANDLE *hthread;
19 #else
20 #include <pthread.h>
21 #include <sys/time.h>
22 pthread_t *hthread;
23 #endif
24
25 typedef struct {
26 int nthread;
27 int tid;
28 int n;
29 const float *a;
30 const float *b;
31 double sum;
32 } thread_arg_t;
33
34 static void sdot_thread(void *arg)
35 {
36 thread_arg_t *targ = (thread_arg_t *)arg;
37 int nthread = targ->nthread;
38 int tid = targ->tid;
39 int n = targ->n;
40 const float *a = targ->a;
41 const float *b = targ->b;
42
43 // (1) block
44 int block = (n + nthread - 1) / nthread;
45 int i0 = tid * block;
46 int i1 = (tid + 1) * block;
47 if (i1 > n) i1 = n;
48 double sum = 0;
49 for (int i = i0; i < i1; i++) {
50 sum += a[i] * b[i];
51 }
52 /*
53 // (2) cyclic
54 double sum = 0;
55 for (int i = tid; i < n; i += nthread) {
56 sum += a[i] * b[i];
57 }
58 */
59 targ->sum = sum;
60 }
61
62 static double sdot(int n, const float a[], const float b[], int nthread)
63 {
64 // thread arguments
65 thread_arg_t *targ = (thread_arg_t *)malloc(nthread * sizeof(thread_arg_t));
66 for (int tid = 0; tid < nthread; tid++) {
67 targ[tid].nthread = nthread;
68 targ[tid].tid = tid;
69 targ[tid].n = n;
70 targ[tid].a = a;
71 targ[tid].b = b;
72 }
73
74 // multi thread
75 if (nthread > 1) {
76 #ifdef _WIN32
77 for (int tid = 0; tid < nthread; tid++) {
78 hthread[tid] = CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)sdot_thread, (void *)&targ[tid], 0, NULL);
79 }
80 WaitForMultipleObjects(nthread, hthread, TRUE, INFINITE);
81 for (int tid = 0; tid < nthread; tid++) {
82 CloseHandle(hthread[tid]);
83 }
84 #else
85 for (int tid = 0; tid < nthread; tid++) {
86 pthread_create(&hthread[tid], NULL, (void *)sdot_thread, (void *)&targ[tid]);
87 }
88 for (int tid = 0; tid < nthread; tid++) {
89 pthread_join(hthread[tid], NULL);
90 }
91 #endif
92 }
93 // single thread
94 else {
95 sdot_thread((void *)targ);
96 }
97
98 // sum
99 double sum = 0;
100 for (int tid = 0; tid < nthread; tid++) {
101 sum += targ[tid].sum;
102 }
103
104 return sum;
105 }
106
107 int main(int argc, char **argv)
108 {
109 int nthread = 1;
110 int n = 1000;
111 int nloop = 1000;
112 #ifdef _WIN32
113 clock_t t0, t1;
114 #else
115 struct timeval t0, t1;
116 #endif
117
118 // arguments
119 if (argc >= 4) {
120 n = atoi(argv[1]);
121 nloop = atoi(argv[2]);
122 nthread = atoi(argv[3]);
123 }
124
125 // thread
126 #ifdef _WIN32
127 hthread = (HANDLE *)malloc(nthread * sizeof(HANDLE));
128 #else
129 hthread = (pthread_t *)malloc(nthread * sizeof(pthread_t));
130 #endif
131
132 // alloc
133 size_t size = n * sizeof(float);
134 float *a = (float *)malloc(size);
135 float *b = (float *)malloc(size);
136
137 // setup problem
138 for (int i = 0; i < n; i++) {
139 a[i] = i + 1.0f;
140 b[i] = i + 1.0f;
141 }
142
143 // timer
144 #ifdef _WIN32
145 t0 = clock();
146 #else
147 gettimeofday(&t0, NULL);
148 #endif
149
150 // calculation
151 double sum = 0;
152 for (int loop = 0; loop < nloop; loop++) {
153 sum += sdot(n, a, b, nthread);
154 }
155
156 // timer
157 double cpu = 0;
158 #ifdef _WIN32
159 t1 = clock();
160 cpu = (double)(t1 - t0) / CLOCKS_PER_SEC;
161 #else
162 gettimeofday(&t1, NULL);
163 cpu = (t1.tv_sec - t0.tv_sec) + 1e-6 * (t1.tv_usec - t0.tv_usec);
164 #endif
165
166 // output
167 double exact = (double)nloop * n * (n + 1) * (2 * n + 1) / 6.0;
168 printf("N=%d L=%d %.6e(%.6e) err=%.1e %.3f[sec] %d\n",
169 n, nloop, sum, exact, fabs((sum - exact) / exact), cpu, nthread);
170
171 // free
172 free(hthread);
173 free(a);
174 free(b);
175
176 return 0;
177 }
並列計算のアルゴリズム
ベクトルの内積を複数のスレッドで並列計算するには、
スレッド間で変数へのアクセスが重複することがないので、
単純にループを分割するだけで済みます。
最後に各スレッドの部分和を加えると全体の和になります。
block型とcyclic型
block型とcyclic型についてはOpenMPを参考にしてください。
リスト6-1のsdot_thread関数のどちらかのコメントを解除してください。
スレッドモデルの違い
VC++とGCCでスレッドモデルが異なるので、以下のように記述します。
#ifdef _WIN32 (VC++用コード) #else (GCC用コード) #endif
計算時間の計測
gccではclock関数は全スレッドの和になるので、
リスト6-1では計算時間を計測するためにgettimeofday関数を使用しています。
コンパイル・リンク方法
VC++ではコンパイル・リンクオプションは特に必要ありません。
> cl.exe /O2 sdot_thread.c
gccではリンクオプション"-lpthread -lm"は環境によっては省略できます。
> gcc -O2 sdot_thread.c -o sdot_thread -lpthread -lm
プログラムの実行方法
プログラムの実行方法は以下の通りです。
> sdot_thread 配列の大きさ 繰り返し回数 スレッド数
例えば以下のようになります。
> sdot_thread 1000000 1000 4
繰り返し回数は計算時間の測定誤差を小さくするためです。
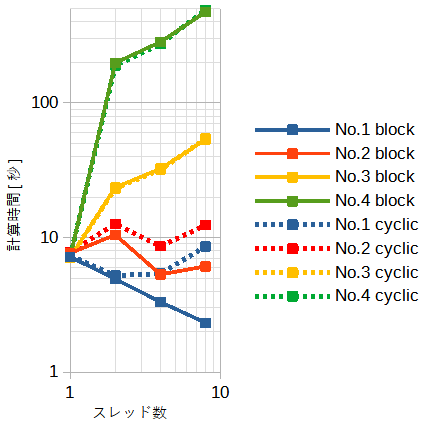
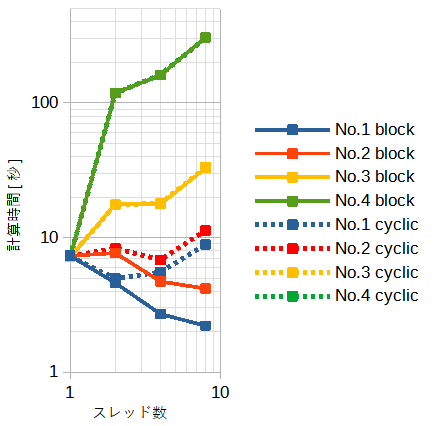
表6-1の各ケースの計算時間を図6-1に示します。
配列の大きさ(=N)と繰り返し回数(=L)の積は一定(=10^10)です。従って全体の演算量は同じです。
表の下になるほど使用メモリーが小さくなりキャッシュに乗りやすくなります。
No.3-4ではスレッドの起動回数が多いために計算時間が増大しています。
このとき、スレッド起動のオーバーヘッド時間が本来の計算時間より大幅に多くなっています。
スレッド起動のオーバーヘッド時間はスレッド起動回数とスレッド数の積にほぼ比例し、
VC++はGCCの約2倍です。
スレッド起動回数の少ないNo.1のblock型ではスレッド数を増やすと計算時間が小さくなります。
block/cyclic型のどちらがよいかはOpenMPと同じく問題の性質で変わる可能性があります。
| No. | 配列の大きさN | 繰り返し回数L |
|---|---|---|
| 1 | 10,000,000 | 1,000 |
| 2 | 1,000,000 | 10,000 |
| 3 | 100,000 | 100,000 |
| 4 | 10,000 | 1,000,000 |