MPI(Message Passing Interface)とは複数台のコンピュータで計算処理を分割し計算時間を短縮するものです。
実行単位をプロセスと呼びます。プロセス間の通信によりデータのやり取りを行います。
1台のコンピュータのマルチコア/マルチCPUで並列計算することもできます。
MPI関数
MPIの関数はたくさんありますが、表7-1によく使用する関数を載せます。
これだけの関数とその派生関数を理解しておけばたいていの実用プログラムができます。
また、MPIはOSに依存しない規格なので、同じソースコードがWindowsとLinuxで動きます。
| No. | 関数名 | 機能 |
|---|---|---|
| 1 | MPI_Init | すべてのMPI関数を呼ぶ前に呼びます。必須です。 |
| 2 | MPI_Comm_size | プロセスの数を取得します。必須です。 |
| 3 | MPI_Comm_rank | 自分のプロセス番号を取得します。必須です。 |
| 4 | MPI_Finalize | すべてのMPI関数の後に呼びます。必須です。本関数を呼ばずにプログラムを終了させるとエラーが発生します。 |
| 5 | MPI_Bcast | 特定のプロセスからすべてのプロセスにデータを送信します。入力データを全プロセスで共有するときに使用します。集団通信 |
| 6 | MPI_Reduce | すべてのプロセスのデータに指定した操作を加え結果を特定のプロセスに格納します。集団通信 |
| 7 | MPI_Send | 指定したプロセスにデータを送信します。1対1通信 |
| 8 | MPI_Recv | 指定したプロセスからデータを受信します。1対1通信 |
| 9 | MPI_Sendrecv | 指定したプロセスと送信を受信を同時に行います。MPI_SendとMPI_Recvを同時に使ってデッドロックが発生するとき安全に通信できます。1対1通信 |
| 10 | MPI_Scatter | 指定した配列を分割して順に各プロセスに分配します。集団通信 |
| 11 | MPI_Gather | 各プロセスから集めたデータを一つの配列に格納します。集団通信 |
| 12 | MPI_Barrier | 全プロセスの同期をとります。集団通信 |
| 13 | MPI_Wtime | 現在の時刻を取得します。 |
1対1通信と集団通信
1対1通信とは一つの送信プロセスと一つの受信プロセスの間でデータのやり取りを行うことです。
送受信プロセスは同期が取られますがその他のプロセスは独立に動いています。
関数の引数で送信プロセス番号と受信プロセス間番号を指定します。
集団通信とはすべてのプロセスで同期を取ってすべてのプロセスが関与する処理を行うことです。
すべてのプロセスが同じタイミングでプログラムのその箇所に到達するとき効率よく計算することができます。
逆に一つでも遅れるとアイドル状態が発生し全体の計算時間が増えることになります。
通信は一般に計算コストがかかるので、なるべく通信回数を少なくし、通信量を減らすことが大切です。
並列版と逐次版の開発
MPIプログラムではデータの分割でバグが発生しやすくなります。
そこで開発にあたっては先ずMPI関数を用いない逐次版を作成し、
計算ロジックが正しく動作していることを十分確認してから、
MPI関数を用いた並列版を作成することが普通です。
そのためにマクロ(ここでは"_MPI")のON/OFFを使い分けます。
リスト7-1にベクトル内積をMPIで並列計算するプログラムを示します。
リスト7-1 MPIプログラム(mpi_sdot.c)
1 /*
2 mpi_sdot.c (MPI)
3
4 VC++ : cl.exe /O2 /D_MPI mpi_sdot.c msmpi.lib
5 gcc : mpicc -O2 -D_MPI -o mpi_sdot mpi_sdot.c
6
7 Usage:
8 > mpiexec -n <proc> mpi_sdot <num> <loop>
9 */
10
11 #include <stdlib.h>
12 #include <stdio.h>
13 #include <time.h>
14 #include <math.h>
15
16 #ifdef _MPI
17 #include <mpi.h>
18 #endif
19
20 static double sdot(int n, const float a[], const float b[])
21 {
22 double sum = 0;
23 for (int i = 0; i < n; i++) {
24 sum += a[i] * b[i];
25 }
26
27 return sum;
28 }
29
30 int main(int argc, char **argv)
31 {
32 int comm_size = 1;
33 int comm_rank = 0;
34 int n = 1000;
35 int nloop = 1000;
36 clock_t t0 = 0, t1 = 0;
37
38 // initialize
39 #ifdef _MPI
40 MPI_Init(&argc, &argv);
41 MPI_Comm_size(MPI_COMM_WORLD, &comm_size);
42 MPI_Comm_rank(MPI_COMM_WORLD, &comm_rank);
43 #endif
44
45 // arguments
46 if (argc >= 3) {
47 n = atoi(argv[1]);
48 nloop = atoi(argv[2]);
49 }
50
51 // block
52 const int block = (n + (comm_size - 1)) / comm_size;
53 const int i0 = (comm_rank + 0) * block;
54 int i1 = (comm_rank + 1) * block;
55 if (i1 > n) i1 = n;
56
57 // alloc
58 const size_t size = (i1 - i0) * sizeof(float);
59 float *a = (float *)malloc(size);
60 float *b = (float *)malloc(size);
61
62 // setup problem
63 for (int i = i0; i < i1; i++) {
64 a[i - i0] = i + 1.0f;
65 b[i - i0] = i + 1.0f;
66 }
67
68 // timer
69 if (comm_rank == 0) {
70 t0 = clock();
71 }
72
73 // calculation
74 double sum = 0;
75 for (int loop = 0; loop < nloop; loop++) {
76 double l_c = sdot(i1 - i0, a, b);
77 double g_c = 0;
78 #ifdef _MPI
79 MPI_Reduce(&l_c, &g_c, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
80 #else
81 g_c = l_c;
82 #endif
83 sum += g_c;
84 }
85 sum /= nloop;
86
87 #ifdef _MPI
88 MPI_Finalize();
89 #endif
90
91 // output
92 if (comm_rank == 0) {
93 // timer
94 t1 = clock();
95 const double cpu = (double)(t1 - t0) / CLOCKS_PER_SEC;
96
97 // output
98 const double exact = (double)n * (n + 1) * (2 * n + 1) / 6.0;
99 printf("N=%d L=%d %.6e(%.6e) err=%.1e %.3f[sec] %d\n",
100 n, nloop, sum, exact, fabs((sum - exact) / exact), cpu, comm_size);
101 fflush(stdout);
102 }
103
104 // free
105 free(a);
106 free(b);
107
108 return 0;
109 }
並列計算のアルゴリズム
ベクトル内積をMPIで並列計算するには、
配列をプロセスに分割し、それぞれのプロセスで内積を計算し、
最後に各プロセスの和をMPI_Reduce関数により計算しその結果をルートプロセスに格納します。
配列の分割
ここでは配列を分割する方法としてOpenMPで述べたblock型を使用します。
58-66行目のように各プロセスが部分配列を持つようにすると、
関数sdotが逐次版と並列版で同じになることに注意してください。
これがMPIの使用する技術である
SPMD (Single Program Multiple Data) プログラミングの要の考え方になります。
このようにするとプログラムの作成とデバッグが容易になると同時に、
メモリーの有効利用になるので、
可能な限り配列のとりかたをこのように設計してください。
MPIプログラムの入出力
MPI-1では入出力はルートプロセスだけが行うことができます(92行目)。
MPI-2では並列入出力をサポートしており、
現在のMPI処理系はほとんどMPI-2をサポートしています。
ただし、ここではMPI-1のみを使用します。
コンパイル・リンク方法
VC++の場合:
> cl.exe /O2 /D_MPI sdot_mpi.c msmpi.lib
gccの場合:
> mpicc -O2 -D_MPI -o sdot_mpi sdot_mpi.c
どちらもコンパイルオプション"D_MPI"がないときは逐次版ができます。
プログラムの実行方法
プログラムを実行するにはコマンドプロンプトで以下のコマンドを実行してください。
> mpiexec -n プロセス数 sdot_mpi 配列の大きさ 繰り返し回数
例えば以下のようになります。
> mpiexec -n 4 sdot_mpi 1000000 1000
繰り返し回数は計算時間の測定誤差を小さくするためです。
なお、実行時にセキュリティソフトが警告を出したら[許可]してください。
逐次版を実行するには
> mpiexec -n 1 sdot_mpi 1000000 1000
または単に
> sdot_mpi 1000000 1000
とします。
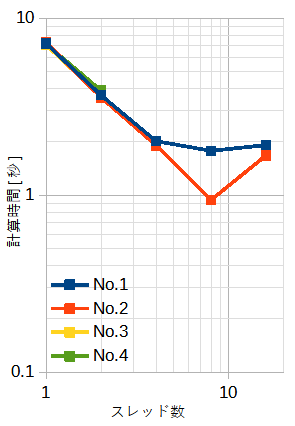
表7-2と図7-1に計算時間を示します。
配列の大きさ(=N)と繰り返し回数(=L)の積は一定(=1010)です。
従って全体の演算量は同じです。
1プロセスではNo.1-4で計算時間はほぼ一定です。
No.1では4プロセスまで、No.2では8プロセスまで、No.3-4では2プロセスまで、
プロセス数に比例して速くなります。
4プロセス以上で繰り返し回数が10万回を超える(No.3-4)と計算時間が極端に増えます。
Microsoft MPI のバグと思われます。
| No. | 配列の大きさN | 繰り返し回数L | 1プロセス | 2プロセス | 4プロセス | 8プロセス | 16プロセス |
|---|---|---|---|---|---|---|---|
| 1 | 10,000,000 | 1,000 | 7.18秒(1.0) | 3.67秒(1.96) | 2.02秒(3.55) | 1.78秒(4.03) | 1.92秒(3.74) |
| 2 | 1,000,000 | 10,000 | 7.29秒(1.0) | 3.57秒(2.04) | 1.91秒(3.82) | 0.94秒(7.76) | 1.68秒(4.34) |
| 3 | 100,000 | 100,000 | 7.07秒(1.0) | 3.60秒(1.96) | 不可 | 不可 | 不可 |
| 4 | 10,000 | 1,000,000 | 7.16秒(1.0) | 3.90秒(1.84) | 不可 | 不可 | 不可 |
MPIは複数台のコンピュータで並列計算することができ、これが本来のMPIの目的です。
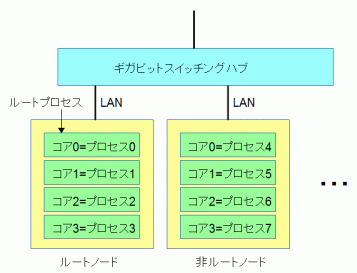
図7-2は複数台のコンピュータをネットワーク接続したクラスタの概念図です。
MPIでは各コンピュータを「ノード」と呼びます。
ユーザーが直接操作するノードをここでは「ルートノード」、
それ以外を「非ルートノード」と呼びます。
ルートノードの最初のコアがルートプロセスになります。
準備作業(Windows環境)
(1) ネットワーク接続
複数台のコンピュータをネットワークで接続します。
ネットワークには Gigabit Ethernet を推奨します。
(2) ユーザー登録
すべてのノードに同じアカウントを同じパスワードで登録します(パスワードなしは不可)。
エクスプローラーの[ネットワーク]ですべてのノードが見えることを確認してください。
ここで表示される名前がノード名になります。ノード名は大文字小文字を区別しません。
(3) MPIインストール
ルートノードに "Microsoft-MPI" [10]をインストールします。
(4) ファイルコピー
非ルートノードにルートノードの実行プログラムがあるフォルダと同じ絶対パスのフォルダを作成し、
そのフォルダにルートノードから以下のファイルをコピーしてください。
すなわち、実行プログラムの絶対パスがすべてのノードで同じであることが必要です。
このフォルダを以下"実行フォルダ"と呼びます。
(5) デーモン起動
ルートノードとすべての非ルートノードでコマンドプロンプトから以下のコマンドを実行してください。
> smpd -p 8677
ここで、"8677"は通信で使用するTCP/IPのポート番号(固定)です。
非ルートノードでの作業は以上で終了です。
ここからの作業はすべてルートノードで行います。
(注意)
1台で計算するときは内部でデーモンが起動されるので(5)の作業は不要です。
準備作業(Linux環境)
(1) ネットワーク接続
複数台のコンピュータをネットワークで接続します。
ネットワークには Gigabit Ethernet を推奨します。
pingコマンドによりネットワーク接続されていることを確認してください。
(2) ユーザー登録
すべてのノードに同じアカウントを登録します。
パスワードも同じにすると便利です。
(3) MPIインストール
すべてのノードで以下のコマンドを実行してください。
$ sudo apt-get install openssh-server (SSHサーバー)
ルートノードで以下のコマンドを実行してください。
$ sudo apt-get install libopenmpi-dev (MPI開発環境)
すべての非ルートノードで以下のコマンドを実行してください。
$ sudo apt-get install openmpi-bin (MPI実行環境)
(4) ファイルコピー
非ルートノードにルートノードのMPI対応実行プログラムがあるディレクトリと同じ絶対パスのディレクトリを作成し、
そのディレクトリにルートノードから実行プログラムをコピーしてください。
すなわち、実行プログラムの絶対パスがすべてのノードで同じであることが必要です。
非ルートノードでの作業は以上で終了です。
ここからの作業はすべてルートノードで行います。
プログラム実行(Windows環境)
ここでは2台のコンピュータが接続され、非ルートノード名を"PC2"とします。
ルートノードでコマンドプロンプトを起動して実行フォルダに移動し、
以下のコマンドを実行してください。
> mpiexec -hosts 2 localhost 4 PC2 4 プログラム [引数]
ここで、-hostsの次の数字は全体のノード数であり、
その後にノード名とそのノードで起動するプロセス数の対をノード数だけ並べます。
または以下の方法もあります。
> mpiexec -configfile mpi.cfg
ここで、mpi.cfgは引数(mpiexecの後の文字列)を記したテキストファイルであり、
そのファイル名は任意です。
mpi.cfgファイルをテキストエディタで開き、上の例では下記の内容を入力してください。
-hosts 2 localhost 4 PC2 4 プログラム [引数]mpiexecの使用法についてはコマンドプロンプトで単に"mpiexec"と行ってください。
プログラム実行(Linux環境)
ここでは2台のコンピュータが接続され、非ルートノード名を"PC2"とします。
ルートノードでコマンドラインで実行フォルダに移動し、
以下のコマンドを実行してください。
$ mpiexec -hostfile hostfile プログラム [引数]
hostfileはホスト名とプロセス数を記したテキストファイルであり、
そのファイル名は任意です。
hostfileの内容は例えば以下のようになります。
localhost slots=4 PC2 slots=4第1行がルートノード、第2行以降が非ルートノードであり、 最初の文字列がホスト名、"slots="の後の数字がそのノードで起動するプロセスの数です。 ホスト名の代わりにIPアドレスでも構いません。