NVIDIAまたはAMDのグラフィックスボード(GPU)が搭載されたコンピュータでは、
その高い演算能力を汎用的な科学技術計算に用いることができます。
そのためのプログラミング言語をOpenCL(Open Computing Language)と呼びます。
CPUがフロントエンドとして動作し、計算の主要部はGPUが行います。
OpenCLプログラムはCPUやCPU内蔵GPUでも動作しますが性能上の利点は少なく主に外付GPUで使用します。
OpenCLプログラム
OpenCLプログラムは通常のC/C++で記述されるホストプログラムと、
OpenCL C言語で記述されるカーネルプログラム(拡張子.cl)から成ります。
ホストプログラムはCPUで実行され、カーネルプログラムはGPUで実行されます。
両者の関係はCUDAと同じです。
OpenCL C言語
カーネルを記述するOpenCL C言語のC/C++との違いは以下の通りです。
オンラインコンパイルとオフラインコンパイル
OpenCLプログラムにはオンラインコンパイルとオフラインコンパイルの2種類のモードがあります。
それぞれの意味は以下の通りです。
OpenCLプログラミングの指針
OpenCLプログラミングでは以下の点が最も重要です。これはCUDAと同じです。
(1)並列計算できるアルゴリズムを採用する。
(2)CPU/GPU間のデータ転送を最小限にする。
(3)カーネルコードではメモリアクセスをスレッド順とする。
これらを満たさないときは速度は数分の一以下になりGPUを使う意味がなくなります。
変数の命名ルール
CPUコードとGPUコードの両方から呼ばれる同じ意味をもつ変数については、
前者の頭には何もつけないか"h_"(host memoryの意味)を付け、
後者の頭に"d_"(device memoryの意味)を付ける方法がよく用いられます。
このようにすればその変数がCPUにあるかGPUにあるか一目でわかります。
またカーネル変数の名前はカーネル関数の名前と1対1に対応させるとわかりやすくなります。
データ並列とタスク並列
並列処理にはデータ並列とタスク並列の2種類がありますが、数値計算では通常前者を使用します。
OpenCLではそのための関数がclEnqueueNDRangeKernel関数です。
ワークアイテム
OpenCLではスレッドのことをワークアイテムと呼び、スレッドの集合をグループと呼びます。
ワークアイテムの大きさはclEnqueueNDRangeKernel関数の引数で指定します。
表9-1にOpenCLとCUDAの対応関係を示します。
カーネル関数でこれらを通して自分のスレッド番号を取得します。
OpenCLではNo.5,No.6も関数が用意されており便利です。
| No. | OpenCL ワークアイテム | CUDA execution configuration |
|---|---|---|
| 1 | get_local_id(0) get_local_id(1) get_local_id(2) | threadIdx.x threadIdx.y threadIdx.z |
| 2 | get_local_size(0) get_local_size(1) get_local_size(2) | blockDim.x blockDim.y blockDim.z |
| 3 | get_group_id(0) get_group_id(1) get_group_id(2) | blockIdx.x blockIdx.y blockIdx.z |
| 4 | get_num_groups(0) get_num_groups(1) get_num_groups(2) | gridDim.x gridDim.y gridDim.z |
| 5 | get_global_id(0) get_global_id(1) get_global_id(2) | threadIdx.x+blockIdx.x*blockDim.x threadIdx.y+blockIdx.y*blockDim.y threadIdx.z+blockIdx.z*blockDim.z |
| 6 | get_global_size(0) get_global_size(1) get_global_size(2) | blockDim.x*gridDim.x blockDim.y*gridDim.y blockDim.z*gridDim.z |
ホストプログラム
リスト9-1にベクトルの和をOpenCLで並列計算するプログラムを示します。
リスト9-1 OpenCLホストプログラム(ocl_vadd_v1.c)
1 /*
2 ocl_vadd_v1.c (OpenCL, version 1)
3
4 Compile + Link:
5 > cl.exe /O2 ocl_vadd_v1.c OpenCL.lib
6
7 Usage:
8 > ocl_vadd_v1 <n> <loop> <platform> <device>
9 */
10
11 #include <stdio.h>
12 #include <stdlib.h>
13 #include <time.h>
14 #include <CL/cl.h>
15
16 #define MAX_PLATFORMS (10)
17 #define MAX_DEVICES (10)
18 #define MAX_SOURCE_SIZE (100000)
19
20 int main(int argc, char **argv)
21 {
22 // OpenCL
23 cl_context context = NULL;
24 cl_command_queue command_queue = NULL;
25 cl_program program = NULL;
26 cl_kernel kernel = NULL;
27 cl_platform_id platform_id[MAX_PLATFORMS];
28 cl_device_id device_id[MAX_DEVICES];
29
30 // memory object
31 cl_mem d_a = NULL;
32 cl_mem d_b = NULL;
33 cl_mem d_c = NULL;
34
35 FILE *fp;
36 char *source_str;
37 size_t source_size;
38 size_t global_item_size, local_item_size;
39 size_t ret_size;
40 cl_uint num_platforms;
41 cl_uint num_devices;
42 cl_int ret;
43 char str[BUFSIZ];
44
45 cl_uint platform = 0;
46 cl_uint device = 0;
47 int nloop = 1000;
48 int n = 1000;
49
50 // arguments
51 if (argc >= 5) {
52 n = atoi(argv[1]);
53 nloop = atoi(argv[2]);
54 platform = atoi(argv[3]);
55 device = atoi(argv[4]);
56 }
57
58 // alloc
59 source_str = (char *)malloc(MAX_SOURCE_SIZE * sizeof(char));
60
61 // setup host arrays
62 float *a = (float *)malloc(n * sizeof(float));
63 float *b = (float *)malloc(n * sizeof(float));
64 float *c = (float *)malloc(n * sizeof(float));
65 for (int i = 0; i < n; i++) {
66 a[i] = (float)(1 + i);
67 b[i] = (float)(1 + i);
68 }
69
70 // platform
71 clGetPlatformIDs(MAX_PLATFORMS, platform_id, &num_platforms);
72 if (platform >= num_platforms) {
73 printf("error : platform = %d (limit = %d)\n", platform, num_platforms - 1);
74 exit(1);
75 }
76
77 // device
78 clGetDeviceIDs(platform_id[platform], CL_DEVICE_TYPE_ALL, MAX_DEVICES, device_id, &num_devices);
79 if (device >= num_devices) {
80 printf("error : device = %d (limit = %d)\n", device, num_devices - 1);
81 exit(1);
82 }
83
84 // device name (option)
85 clGetDeviceInfo(device_id[device], CL_DEVICE_NAME, sizeof(str), str, &ret_size);
86 printf("%s\n", str);
87
88 // context
89 context = clCreateContext(NULL, 1, &device_id[device], NULL, NULL, &ret);
90
91 // command queue
92 command_queue = clCreateCommandQueue(context, device_id[device], 0, &ret);
93
94 // source
95 if ((fp = fopen("vadd.cl", "r")) == NULL) {
96 fprintf(stderr, "kernel source open error\n");
97 exit(1);
98 }
99 source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp);
100 fclose(fp);
101
102 // program
103 program = clCreateProgramWithSource(context, 1, (const char **)&source_str, (const size_t *)&source_size, &ret);
104 if (ret != CL_SUCCESS) {
105 fprintf(stderr, "clCreateProgramWithSource() error\n");
106 exit(1);
107 }
108
109 // build
110 if (clBuildProgram(program, 1, &device_id[device], NULL, NULL, NULL) != CL_SUCCESS) {
111 fprintf(stderr, "clBuildProgram() error\n");
112 exit(1);
113 }
114
115 // kernel
116 kernel = clCreateKernel(program, "vadd", &ret);
117 if (ret != CL_SUCCESS) {
118 fprintf(stderr, "clCreateKernel() error\n");
119 exit(1);
120 }
121
122 // memory object
123 d_a = clCreateBuffer(context, CL_MEM_READ_WRITE, n * sizeof(float), NULL, &ret);
124 d_b = clCreateBuffer(context, CL_MEM_READ_WRITE, n * sizeof(float), NULL, &ret);
125 d_c = clCreateBuffer(context, CL_MEM_READ_WRITE, n * sizeof(float), NULL, &ret);
126
127 // host to device
128 clEnqueueWriteBuffer(command_queue, d_a, CL_TRUE, 0, n * sizeof(float), a, 0, NULL, NULL);
129 clEnqueueWriteBuffer(command_queue, d_b, CL_TRUE, 0, n * sizeof(float), b, 0, NULL, NULL);
130
131 // args
132 clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&d_a);
133 clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&d_b);
134 clSetKernelArg(kernel, 2, sizeof(cl_mem), (void *)&d_c);
135 clSetKernelArg(kernel, 3, sizeof(int), (void *)&n);
136
137 // timer
138 clock_t t0 = clock();
139
140 // work item
141 local_item_size = 256;
142 global_item_size = ((n + local_item_size - 1) / local_item_size) * local_item_size;
143
144 // run
145 for (int loop = 0; loop < nloop; loop++) {
146 clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL, &global_item_size, &local_item_size, 0, NULL, NULL);
147 }
148
149 // device to host
150 clEnqueueReadBuffer(command_queue, d_c, CL_TRUE, 0, n * sizeof(float), c, 0, NULL, NULL);
151
152 // timer
153 clock_t t1 = clock();
154 double cpu = (double)(t1 - t0) / CLOCKS_PER_SEC;
155
156 // output
157 double sum = 0;
158 for (int i = 0; i < n; i++) {
159 sum += c[i];
160 }
161 double exact = n * (n + 1.0);
162 printf("n=%d nloop=%d %e(%.6e) cpu[sec]=%.3f\n",
163 n, nloop, sum, exact, cpu);
164
165 // release
166 clFlush(command_queue);
167 clFinish(command_queue);
168 clReleaseMemObject(d_a);
169 clReleaseMemObject(d_b);
170 clReleaseMemObject(d_c);
171 clReleaseKernel(kernel);
172 clReleaseProgram(program);
173 clReleaseCommandQueue(command_queue);
174 clReleaseContext(context);
175
176 // free
177 free(source_str);
178 free(a);
179 free(b);
180 free(c);
181
182 return 0;
183 }
ソースコードの説明
14行目:OpenCLプログラムにはこのinclude文が必須です。
70-120行目:OpenCLに必須の前処理です。OpenCLはいろいろな環境で動くためにこのような処理が必要になります。
コードが煩雑になりますが定型的な処理です。
platform→device→context→command queue→カーネルソースコード→program→build→kernelの順に処理します。
78行目:"CL_DEVICE_TYPE_ALL"を"CL_DEVICE_TYPE_GPU"に変えるとGPUだけが対象デバイスになります。
123-125行目:GPUで使用する配列を確保します。(CUDAのcudaMallocに対応)
128-129行目:ホストからデバイスにメモリーを転送します。(CUDAのcudaMemcpy(...,cudaMemcpyHostToDevice)に対応)
132-135行目:カーネルの引数を代入します。(CUDAにない機能)
141-142行目:ワークアイテム(スレッドの構成)を指定します。global_item_sizeはlocal_item_sizeの整数倍であることが必要です。(CUDAのExecution configurationに対応)
150行目:デバイスからホストにメモリーを転送します。(CUDAのcudaMemcpy(...,cudaMemcpyDeviceToHost)に対応)
168-170行目:GPUで使用した配列を解放します。(CUDAのcudaFreeに対応)
カーネルプログラム
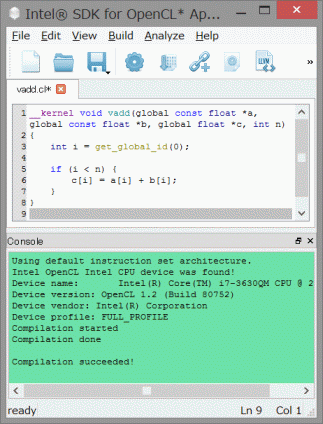
リスト9-2にカーネルプログラムを示します。
オンラインコンパイルではカーネルプログラムを実行プログラムと同じフォルダに置きます。
リスト9-2 OpenCLカーネルプログラム(vadd.cl)
1 __kernel void vadd(global const float *a, global const float *b, global float *c, int n)
2 {
3 int i = get_global_id(0);
4
5 if (i < n) {
6 c[i] = a[i] + b[i];
7 }
8 }
ソースコードの説明
3行目:globalなスレッド番号を取得します。それがこの場合配列のインデックスになります。
5行目:配列の大きさはスレッド数の倍数とは限らないのでこの条件判定が必要です。
プログラミングの改良
上で示したプログラムはOpenCLを用いた最小のプログラムですが、
大規模なアプリケーションを開発するための出発点としては不適切です。
すわなちOpenCL固有の処理とその他の処理が分離されておらず、
また計算アルゴリズムを検証するための逐次計算が実装されていないために開発効率が悪くなります。
その点を考慮したプログラムをリスト9-3に示します。
なお、カーネルプログラムはリスト9-2と共通です。
リスト9-3 OpenCLホストプログラム(ocl_vadd_v2.c)
1 /*
2 ocl_vadd_v2.c (OpenCL, version 2)
3
4 Compile + Link:
5 > cl.exe /O2 ocl_vadd_v2.c OpenCL.lib
6
7 Usage:
8 > ocl_vadd_v2 <n> <loop> <platform> <device>
9 */
10
11 #include <stdio.h>
12 #include <stdlib.h>
13 #include <string.h>
14 #include <time.h>
15
16 #ifdef __APPLE__
17 #include <OpenCL/opencl.h>
18 #else
19 #include <CL/cl.h>
20 #endif
21
22 #define MAX_PLATFORMS (10)
23 #define MAX_DEVICES (10)
24 #define MAX_SOURCE_SIZE (100000)
25
26 // prototypes
27 static int setup_ocl(cl_uint, cl_uint, char *);
28 static void vadd_calc(void);
29 static void vadd(void);
30
31 // globals
32 cl_command_queue Queue;
33 cl_kernel k_vadd;
34 int N;
35 float *A, *B, *C;
36 cl_mem d_A, d_B, d_C;
37 int OCL;
38
39 int main(int argc, char **argv)
40 {
41 int platform = 0;
42 int device = 0;
43 int nloop = 1000;
44
45 // arguments
46 N = 1000;
47 if (argc >= 5) {
48 N = atoi(argv[1]);
49 nloop = atoi(argv[2]);
50 platform = atoi(argv[3]);
51 device = atoi(argv[4]);
52 }
53 OCL = (platform >= 0);
54
55 // alloc host arrays
56 size_t size = N * sizeof(float);
57 A = (float *)malloc(size);
58 B = (float *)malloc(size);
59 C = (float *)malloc(size);
60
61 // setup problem
62 for (int i = 0; i < N; i++) {
63 A[i] = (float)(1 + i);
64 B[i] = (float)(1 + i);
65 }
66
67 // setup OpenCL
68 if (OCL) {
69 char msg[BUFSIZ];
70 int ret = setup_ocl((cl_uint)platform, (cl_uint)device, msg);
71 printf("%s\n", msg);
72 if (ret) {
73 exit(1);
74 }
75 }
76
77 // timer
78 clock_t t0 = clock();
79
80 // copy host to device
81 if (OCL) {
82 clEnqueueWriteBuffer(Queue, d_A, CL_TRUE, 0, size, A, 0, NULL, NULL);
83 clEnqueueWriteBuffer(Queue, d_B, CL_TRUE, 0, size, B, 0, NULL, NULL);
84 }
85
86 // run
87 for (int loop = 0; loop < nloop; loop++) {
88 vadd_calc();
89 }
90
91 // copy device to host
92 if (OCL) {
93 clEnqueueReadBuffer(Queue, d_C, CL_TRUE, 0, size, C, 0, NULL, NULL);
94 }
95
96 // timer
97 clock_t t1 = clock();
98 double cpu = (double)(t1 - t0) / CLOCKS_PER_SEC;
99
100 // sum
101 double sum = 0;
102 for (int i = 0; i < N; i++) {
103 sum += C[i];
104 }
105
106 // output
107 double exact = N * (N + 1.0);
108 printf("N=%d L=%d %.6e(%.6e) %.1e %.3f[sec]\n",
109 N, nloop, sum, exact, fabs((sum - exact) / exact), cpu);
110
111 // release
112 if (OCL) {
113 clReleaseMemObject(d_A);
114 clReleaseMemObject(d_B);
115 clReleaseMemObject(d_C);
116 clReleaseKernel(k_vadd);
117 clReleaseCommandQueue(Queue);
118 }
119
120 // free
121 free(A);
122 free(B);
123 free(C);
124
125 return 0;
126 }
127
128 // setup OpenCL
129 static int setup_ocl(cl_uint platform, cl_uint device, char *msg)
130 {
131 cl_context context = NULL;
132 cl_program program = NULL;
133 cl_platform_id platform_id[MAX_PLATFORMS];
134 cl_device_id device_id[MAX_DEVICES];
135
136 FILE *fp;
137 char *source_str;
138 char str[BUFSIZ];
139 size_t source_size, ret_size, size;
140 cl_uint num_platforms, num_devices;
141 cl_int ret;
142
143 // alloc
144 source_str = (char *)malloc(MAX_SOURCE_SIZE * sizeof(char));
145
146 // platform
147 clGetPlatformIDs(MAX_PLATFORMS, platform_id, &num_platforms);
148 if (platform >= num_platforms) {
149 sprintf(msg, "error : platform = %d (limit = %d)", platform, num_platforms - 1);
150 return 1;
151 }
152
153 // device
154 clGetDeviceIDs(platform_id[platform], CL_DEVICE_TYPE_ALL, MAX_DEVICES, device_id, &num_devices);
155 if (device >= num_devices) {
156 sprintf(msg, "error : device = %d (limit = %d)", device, num_devices - 1);
157 return 1;
158 }
159
160 // device name (option)
161 clGetDeviceInfo(device_id[device], CL_DEVICE_NAME, sizeof(str), str, &ret_size);
162 sprintf(msg, "%s (platform = %d, device = %d)", str, platform, device);
163
164 // context
165 context = clCreateContext(NULL, 1, &device_id[device], NULL, NULL, &ret);
166
167 // command queue
168 Queue = clCreateCommandQueue(context, device_id[device], 0, &ret);
169
170 // source
171 if ((fp = fopen("vadd.cl", "r")) == NULL) {
172 sprintf(msg, "kernel source open error");
173 return 1;
174 }
175 source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp);
176 fclose(fp);
177
178 // program
179 program = clCreateProgramWithSource(context, 1, (const char **)&source_str, (const size_t *)&source_size, &ret);
180 if (ret != CL_SUCCESS) {
181 sprintf(msg, "clCreateProgramWithSource() error");
182 return 1;
183 }
184
185 // build
186 if (clBuildProgram(program, 1, &device_id[device], NULL, NULL, NULL) != CL_SUCCESS) {
187 sprintf(msg, "clBuildProgram() error");
188 return 1;
189 }
190
191 // kernel
192 k_vadd = clCreateKernel(program, "vadd", &ret);
193 if (ret != CL_SUCCESS) {
194 sprintf(msg, "clCreateKernel() error");
195 return 1;
196 }
197
198 // memory object
199 size = N * sizeof(float);
200 d_A = clCreateBuffer(context, CL_MEM_READ_WRITE, size, NULL, &ret);
201 d_B = clCreateBuffer(context, CL_MEM_READ_WRITE, size, NULL, &ret);
202 d_C = clCreateBuffer(context, CL_MEM_READ_WRITE, size, NULL, &ret);
203
204 // release
205 clReleaseProgram(program);
206 clReleaseContext(context);
207
208 // free
209 free(source_str);
210
211 return 0;
212 }
213
214 // entry point
215 static void vadd_calc(void)
216 {
217 if (OCL) {
218 size_t global_item_size, local_item_size;
219
220 // args
221 clSetKernelArg(k_vadd, 0, sizeof(cl_mem), (void *)&d_A);
222 clSetKernelArg(k_vadd, 1, sizeof(cl_mem), (void *)&d_B);
223 clSetKernelArg(k_vadd, 2, sizeof(cl_mem), (void *)&d_C);
224 clSetKernelArg(k_vadd, 3, sizeof(int), (void *)&N);
225
226 // work item
227 local_item_size = 256;
228 global_item_size = ((N + local_item_size - 1) / local_item_size)
229 * local_item_size;
230
231 // run
232 clEnqueueNDRangeKernel(Queue, k_vadd, 1, NULL, &global_item_size, &local_item_size, 0, NULL, NULL);
233 }
234 else {
235 // serial code
236 vadd();
237 }
238 }
239
240 // serial code
241 static void vadd(void)
242 {
243 for (int i = 0; i < N; i++) {
244 C[i] = A[i] + B[i];
245 }
246 }
ソースコードの説明
32-37行目:複数の関数から呼ばれる変数(プログラムの核をなす変数)をグローバル変数にします。
50行目:3番目の引数に負の値を代入するとOpenCLを使用しない逐次計算プログラムになります。
68-75行目:OpenCL固有の前処理は一か所に集めます。
215行目:この関数が計算の入り口になります。この中で並列処理と逐次処理を場合分けしています。
221-224行目:引数の内容は計算の途中で変わることがありますのでカーネルを呼び出す直前に設定します。
227-229行目:ここではワークアイテムをカーネルを呼び出す直前に設定していますが、
これは計算の途中で変わることはありませんので外部で設定しても構いません。
241-246行目:逐次コードを先に作成して十分テストし、計算式が正しく実装されていることを確認します。
逐次版と並列版の開発
プログラムの最終目的が並列計算であってもいきなり並列計算プログラムを実装してもうまく動くことはほとんどありません。
最初に並列化を想定したプログラム構造の逐次版を作成し、
計算式が正しく実装されていることを十分確認してから並列版を実装することが開発の近道です。
並列版固有の処理は以下の通りです。
これらはすべて定型的な作業なので注意深く実装すれば間違いは少なくなります。
コンパイル・リンク方法
コンパイル・リンク方法は以下の通りです(VC++の場合)。
> cl.exe /O2 ocl_vadd_v2.c OpenCL.lib
warningが出たときは以下のようにしてください。
> cl.exe /O2 /wd4996 /wd4201 ocl_vadd_v2.c OpenCL.lib
ここで、OpenCL.libはCUDAをインストールしたときにCUDAと同じ場所に保存されています。
プログラムの実行方法
プログラムの実行方法は以下の通りです。
> ocl_vadd_v2.exe 配列の大きさ 繰り返し回数 プラットフォーム番号 デバイス番号
例えば以下のようになります。
> ocl_vadd_v2.exe 1000000 1000 1 0 (プラットフォーム番号=1, デバイス番号=0のとき)
> ocl_vadd_v2.exe 1000000 1000 -1 0 (OpenCLを用いないで逐次計算するとき)
繰り返し回数は計算時間の測定誤差を小さくするためです。
プラットフォーム番号とデバイス番号については表9-3を参考にしてください。
プログラム実行時に C:\Windows\System32\OpenCL.dll を使用しています。
OpenCLプログラムはCPU/CPU内蔵GPU/外付GPUで計算することができます。
(以下では、CPU内蔵GPUをiGPU、外付GPUをdGPUと呼びます)[21]
計算するハードウェアはOpenCLのプラットフォーム番号とデバイス番号によって選択することができます。
表9-2にベクトル和の計算時間を示します。
配列の大きさ(=N)と繰り返し回数(=L)の積は一定(=1010)です。
従って全体の演算量は同じです。
dGPUではNo.1-2のとき計算時間が大幅に短縮されますが、
No.3-4でカーネル起動回数が増えるために計算時間が増えます。
これはCUDAと同じです。
リスト9-3よりカーネル起動回数は繰り返し回数と同じです。
繰り返し回数が1,000,000回のときdGPUで約7秒余分に時間がかかっています。
これからdGPUのカーネル起動のオーバーヘッドは約7μsecと評価することができます。
(通常のアプリケーションではカーネルをこのように多数回呼ぶことは少ないです)
iGPUはCPU1コアより速いですが、
CPUは通常マルチコアで並列計算するのでiGPUでOpenCLプログラムを使用する理由は特にありません。
(iGPUはメモリー容量も小さい)
表9-2の外付GPUの計算時間は表8-3のGPUとほぼ同じです。
すなわちCUDAとOpenCLの性能はほぼ同じと言えます。
| No. | 配列の大きさN | 繰り返し回数L | CPU1コア | CPU内蔵GPU (iGPU) | 外付GPU (dGPU) |
|---|---|---|---|---|---|
| 1 | 10,000,000 | 1,000 | 5.79秒 (1.0) | 2.85秒 (2.0) | 0.56秒 (10.3) |
| 2 | 1,000,000 | 10,000 | 7.80秒 (1.0) | 2.85秒 (2.7) | 0.53秒 (14.7) |
| 3 | 100,000 | 100,000 | 3.81秒 (1.0) | 2.62秒 (1.5) | 0.93秒 (4.1) |
| 4 | 10,000 | 1,000,000 | 3.78秒 (1.0) | 2.09秒 (1.8) | 8.03秒 (0.5) |
表9-3に本環境のプラットフォーム番号とデバイス番号を示します。
プラットフォーム番号とデバイス番号は環境によって変わるので、
いろいろ変えて実行し表示されるデバイス名から番号を決定してください。
外付GPUが2個以上あるときは、デバイス番号が順に0,1,...となります。
| No. | ハードウェア | プラットフォーム番号 | デバイス番号 |
|---|---|---|---|
| 0 | CPU | - | - |
| 1 | CPU内蔵GPU | 0 | 0 |
| 2 | 外付GPU | 1 | 0 |