MPI(Message Passing Interface)とは複数台のコンピュータで計算処理を分割し計算時間を短縮するものです。
実行単位をプロセスと呼びます。プロセス間の通信によりデータのやり取りを行います。
1台のコンピュータのマルチコアやマルチCPUで並列計算することもできます。
MPI for Python 関数
MPIの関数はたくさんありますが、表4-1に MPI for Python でよく使用する関数を載せます。
これだけの関数とその派生関数を理解しておけばたいていの実用プログラムができます。
なお、C版のMPIで必須であるInit関数とFinalize関数はありません。
| No. | 関数プロトタイプ | 機能 |
|---|---|---|
| 1 | Get_size() | プロセスの数を取得します。必須です。 |
| 2 | Get_rank() | 自分のプロセス番号を取得します。必須です。 |
| 3 | Bcast(buf[, root]) | 特定のプロセスからすべてのプロセスにデータを送信します。入力データを全プロセスで共有するときに使用します。集団通信 |
| 4 | Reduce(sendbuf, recvbuf[, op, root]) | すべてのプロセスのデータに指定した操作を加え結果を特定のプロセスに格納します。集団通信 |
| 5 | Send(buf, dest[, tag]) | 指定したプロセスにデータを送信します。1対1通信 |
| 6 | Recv(buf[, source, tag, status]) | 指定したプロセスからデータを受信します。1対1通信 |
| 7 | Sendrecv(sendbuf, recvbuf[, root]) | 指定したプロセスと送信を受信を同時に行います。MPI_SendとMPI_Recvを同時に使ってデッドロックが発生するとき安全に通信できます。1対1通信 |
| 8 | Scatter(sendbuf, recvbuf[, root]) | 指定した配列を分割して順に各プロセスに分配します。集団通信 |
| 9 | Gather(sendbuf, recvbuf[, root]) | 各プロセスから集めたデータを一つの配列に格納します。集団通信 |
| 10 | Barrier() | 全プロセスの同期をとります。集団通信 |
リスト4-1に MPI for Python を用いてベクトル内積を並列計算するプログラムを示します。
リスト4-1 MPI for Python によるベクトル内積のソースコード
(sdot_mpi.py)
"""
sdot_mpi.py
scalar product of two vectors
MPI for Python (mpi4py)
"""
import numpy as np
from numba import jit
from mpi4py import MPI
# (sdot-1) Numba
@jit(cache=True, nopython=True)
def sdot_numba(a, b):
n = len(a)
s = 0
for i in range(n):
s += a[i] * b[i]
return s
# (sdot-2) for (very slow)
def sdot_for(a, b):
n = len(a)
s = 0
for i in range(n):
s += a[i] * b[i]
return s
# parameters
N = 10000000
L = 1000
fn = 'sdot-1'
dtype = 'f4' # 'f4' or 'f8'
# MPI
comm = MPI.COMM_WORLD
comm_size = comm.Get_size()
comm_rank = comm.Get_rank()
# timer
comm.Barrier()
t0 = MPI.Wtime()
# alloc
block = (N + (comm_size - 1)) // comm_size
i0 = (comm_rank + 0) * block
i1 = (comm_rank + 1) * block
i1 = min(i1, N)
a = np.zeros(i1 - i0, dtype=dtype)
b = np.zeros(i1 - i0, dtype=dtype)
# setup problem
a[:] = i0 + np.arange(i1 - i0)
b[:] = a[:]
# timer
comm.Barrier()
t1 = MPI.Wtime()
# calculation
s = np.zeros(1, dtype=dtype)
for _ in range(L):
if fn == 'sdot-1':
l_s = sdot_numba(a, b)
elif fn == 'sdot-2':
l_s = sdot_for(a, b)
l_s = np.array(l_s).astype(dtype)
comm.Reduce(l_s, s)
# timer
comm.Barrier()
t2 = MPI.Wtime()
# output
if comm_rank == 0:
exact = N * (N - 1) * (2 * N - 1) / 6
print('(%s) N=%d, L=%d, Np=%d' % (fn, N, L, comm_size))
print('%.2f+%.2f[sec], %e, %e' % (t1 - t0, t2 - t1, s[0], exact))
# free
a = None
b = None
Windowsで MPI for Python プログラムを実行するには、
Microsoft MPI [8]をインストールする必要があります。
その後、Windowsターミナルを起動して、sdot_mpi.py ファイルがあるフォルダに移動した後、
以下のコマンドを実行します。
> mpiexec.exe -n 8 python.exe sdot_mpi.py (数字はプロセス数)
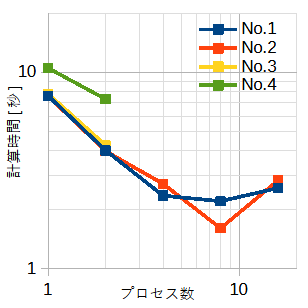
表4-2と図4-1に MPI for Python の計算時間を示します。
配列の大きさ(=N)と繰り返し回数(=L)の積は一定(=1010)です。
従って全体の演算量は同じです。
| No. | 配列の大きさN | 繰り返し回数L | 1プロセス | 2プロセス | 4プロセス | 8プロセス | 16プロセス |
|---|---|---|---|---|---|---|---|
| 1 | 10,000,000 | 1,000 | 6.22秒(1.0) | 3.20秒(1.94) | 1.75秒(3.55) | 1.64秒(3.79) | 1.72秒(3.62) |
| 2 | 1,000,000 | 10,000 | 6.19秒(1.0) | 3.21秒(1.93) | 1.76秒(3.52) | 1.71秒(3.62) | 1.93秒(3.21) |
| 3 | 100,000 | 100,000 | 6.19秒(1.0) | 3.22秒(1.92) | 1.77秒(3.50) | 1.63秒(3.80) | 1.82秒(3.40) |
| 4 | 10,000 | 1,000,000 | 6.18秒(1.0) | 3.22秒(1.92) | 1.75秒(3.53) | 1.66秒(3.72) | 1.77秒(3.49) |
表4-2と図4-1から以下のことがわかります。