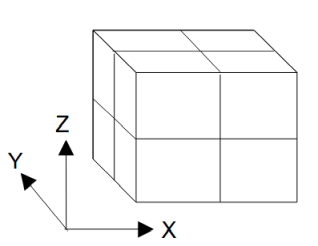
図4-3-1 計算領域のプロセスへの分割(X分割=2、Y分割=2、Z分割=2、プロセス数=8の場合)
MPIを用いて並列計算するには図4-3-1のように計算領域を分割します。
CPU版とGPU版の両方に適用することができます。
プロセス数をPとすると計算時間が1/Pになります。
反復計算時の各プロセスの必要メモリーは1/Pですが、
計算結果をファイルに保存するときに、
CPUのルートプロセスが全領域の電磁界を持ちます。
図4-3-1 計算領域のプロセスへの分割(X分割=2、Y分割=2、Z分割=2、プロセス数=8の場合)
MPIではタイムステップごとに計算領域の境界で隣のプロセスとの通信が必要になります。
通信する成分は図4-3-2の青色すなわちHy,Hz成分です。
プロセスPのHy,HzをプロセスP+1に送信し、
プロセスP+1のHy,HzをプロセスPに送信します。
通信量は8NyNzワードです。
境界線上にある赤色すなわちEy,Ez,Hx成分は両方のプロセスで重複して持ち、
両方のプロセスで更新されます。
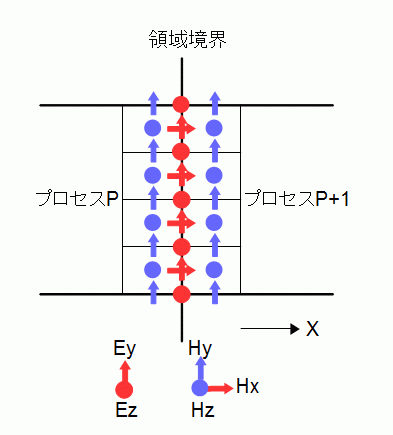
図4-3-2 電磁界の通信(X方向に分割したとき)
リスト4-3-1に電磁界を通信する関数を示します。
通信に用いるバッファ配列とその長さを予め用意しています。
プロセスPの-X境界でプロセスP-1とHy,Hzを送受信し、
その後+X境界でプロセスP+1とHy,Hzを送受信します。
通信にはデッドロックの心配のないMPI_Sendrecv関数を使用します。
リスト4-3-1 電磁界の通信(X方向分割、comm_X.c)
1 // H to buffer
2 static void h_to_buffer(int i, const real_t h[], real_t buf[], const int jrange[], const int krange[])
3 {
4 for (int j = jrange[0]; j <= jrange[1]; j++) {
5 for (int k = krange[0]; k <= krange[1]; k++) {
6 const int64_t m = (j - jrange[0]) * (krange[1] - krange[0] + 1) + (k - krange[0]);
7 buf[m] = h[NA(i, j, k)];
8 }
9 }
10 }
11
12 // buffer to H
13 static void buffer_to_h(int i, const real_t buf[], real_t h[], const int jrange[], const int krange[])
14 {
15 for (int j = jrange[0]; j <= jrange[1]; j++) {
16 for (int k = krange[0]; k <= krange[1]; k++) {
17 const int64_t m = (j - jrange[0]) * (krange[1] - krange[0] + 1) + (k - krange[0]);
18 h[NA(i, j, k)] = buf[m];
19 }
20 }
21 }
22
23 void comm_X(int mode)
24 {
25 #ifdef _MPI
26 MPI_Status status;
27 const int tag = 0;
28 int bx[][2] = {{Ipx > 0, Ipx < Npx - 1}, {Ipx == 0, Ipx == Npx - 1}};
29 int px[][2] = {{Ipx - 1, Ipx + 1}, {Npx - 1, 0}};
30 int irecv[] = {iMin - 1, iMax + 0};
31 int isend[] = {iMin + 0, iMax - 1};
32 int i;
33
34 for (int side = 0; side < 2; side++) {
35 if (bx[mode][side]) {
36 // H to buffer
37 i = isend[side];
38 h_to_buffer(i, Hy, Sendbuf_hy_x, Bid.jhy_x, Bid.khy_x);
39 h_to_buffer(i, Hz, Sendbuf_hz_x, Bid.jhz_x, Bid.khz_x);
40
41 // MPI
42 const int ipx = px[mode][side];
43 const int dst = (ipx * Npy * Npz) + (Ipy * Npz) + Ipz;
44 MPI_Sendrecv(Sendbuf_hy_x, Bid.numhy_x, MPI_REAL_T, dst, tag,
45 Recvbuf_hy_x, Bid.numhy_x, MPI_REAL_T, dst, tag, MPI_COMM_WORLD, &status);
46 MPI_Sendrecv(Sendbuf_hz_x, Bid.numhz_x, MPI_REAL_T, dst, tag,
47 Recvbuf_hz_x, Bid.numhz_x, MPI_REAL_T, dst, tag, MPI_COMM_WORLD, &status);
48
49 // buffer to H
50 i = irecv[side];
51 buffer_to_h(i, Recvbuf_hy_x, Hy, Bid.jhy_x, Bid.khy_x);
52 buffer_to_h(i, Recvbuf_hz_x, Hz, Bid.jhz_x, Bid.khz_x);
53 }
54 }
55 #endif
56 }
収束判定に用いる平均電磁界については各プロセスの部分和の和を計算し、
結果を全プロセスで共有し全プロセスで収束判定を行います。
リスト4-3-2にソースコードを示します。
上記の作業を行うためにMPI_Allreduce関数を使用しています。
リスト4-3-2 平均電磁界の通信
1 void comm_average(double fsum[])
2 {
3 #ifdef MPI
4 double ftmp[2];
5
6 MPI_Allreduce(fsum, ftmp, 2, MPI_DOUBLE, MPI_SUM, MPI_COMM_WORLD);
7
8 fsum[0] = ftmp[0];
9 fsum[1] = ftmp[1];
10 #endif
11 }
反復計算のタイムステップごとに給電点と観測点の時間波形を配列に保存し、
反復計算が終了した後、時間波形をルートプロセスに集めます。
リスト4-3-3に給電点に関するソースコードを示します。
給電点が非ルートプロセスの領域にあるときだけ通信が必要になります。
給電点を有しているプロセスが時間波形をルートプロセスに送信し、
ルートプロセスがそれを受信します。
リスト4-3-3 時間波形の通信
1 void comm_feed(void)
2 {
3 #ifdef _MPI
4 MPI_Status status;
5
6 const int count = Solver.maxiter + 1;
7 for (int n = 0; n < NFeed; n++) {
8 const int i = Feed[n].i;
9 const int j = Feed[n].j;
10 const int k = Feed[n].k;
11 // non-root only
12 if ((commRank == 0) && !comm_inproc(i, j, k)) {
13 MPI_Recv(&VFeed[n * count], count, MPI_DOUBLE, MPI_ANY_SOURCE, 0, MPI_COMM_WORLD, &status);
14 MPI_Recv(&IFeed[n * count], count, MPI_DOUBLE, MPI_ANY_SOURCE, 0, MPI_COMM_WORLD, &status);
15 }
16 else if ((commRank > 0) && comm_inproc(i, j, k)) {
17 MPI_Send(&VFeed[n * count], count, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
18 MPI_Send(&IFeed[n * count], count, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
19 }
20 MPI_Barrier(MPI_COMM_WORLD);
21 }
22 #endif
23 }
表4-3-1にプロセス数を1~16と変えたときの計算時間を示します。
表4-2-1のOpenMPの計算時間とほぼ同じです。
従って、OpenMPと同じく使用メモリーの少ないnovectorモードを推奨します。
また、ハイパースレッディングの効果はないのでプロセス数には物理コア数を推奨します。
| プロセス数 | novector | vector |
|---|---|---|
| 1 | 38.6秒 (1.0) | 36.4秒 (1.0) |
| 2 | 20.0秒 (1.9) | 19.5秒 (1.9) |
| 4 | 12.2秒 (3.2) | 14.1秒 (2.6) |
| 8 | 13.0秒 (3.0) | 15.6秒 (2.3) |
| 16 | 18.0秒 (2.1) | 19.8秒 (1.8) |
表4-3-2にベンチマーク問題を変えたときの計算時間を示します。
表4-2-2のOpenMPの計算時間とほぼ同じです。
| ベンチマーク | novector | vector |
|---|---|---|
| 100 | 13.0秒 | 15.6秒 |
| 200 | 101.8秒 | 118.1秒 |
| 300 | 347.3秒 | 410.6秒 |
| 400 | 781.8秒 | 832.3秒 |
OpenFDTDはOpenMPとMPIで並列化されているのでそれらを併用することができます。
CPUのコア数をOpenMPのスレッド数とMPIのプロセス数に分割します。
表4-3-3は8コアのCPUの結果です。
どのように分割しても計算時間はほぼ同じです。
| MPIプロセス数 | OpenMPスレッド数 | 計算時間 |
|---|---|---|
| 1 | 8 | 108.3秒 |
| 2 | 4 | 97.3秒 |
| 4 | 2 | 97.7秒 |
| 8 | 1 | 101.4秒 |
MPIでは図4-3-1のように3方向に領域分割することができます。
表4-3-4は8プロセスでXYZ方向の領域分割数を変えたときの計算時間です。
領域分割数については一般に、
X方向分割数 >= Y方向分割数 >= Z方向分割数
のとき効率よくなります。
さらに、OpenMPを併用して通信量を減らすことも有効です。
| 領域分割数 | 計算時間 |
|---|---|
| 8x1x1 | 101.4秒 |
| 4x2x1 | 99.5秒 |
| 2x2x2 | 101.7秒 |
| 1x2x4 | 106.2秒 |
| 1x1x8 | 119.2秒 |