図4-4-1 reductionの概念図
CUDAによるFDTD法の高速化では下記の点に注意してプログラムを作成します。
リスト4-4-1にEx成分を更新する関数を示します。
[3]の手法を用いてCPUコードとGPUコードを共通化しています。
なお、MPIとソースコードを共通化するためにX方向に領域分割した記述にしています。
ソースコードの説明
1行目:計算の実体である関数はCPUとGPUで共通です。
従って関数修飾子"__host__ __device__"を付けます。
12行目:GPUコードには関数修飾子"__global__"を付けます。
18-20行目:gridとblockからi,j,kを計算します。
21-23行目:i,j,kが範囲内にあるときだけ計算を行います(セル数がブロックサイズの倍数とは限らないため)。
53-56行目:blockは内側から順にk,j,iとします。
アドレスはkについて連続ですのでこのようにする必要があります(coalescing of memory)。
CEILは繰り上げ商を計算する自作マクロでありCUDAでは頻繁に使われます。
61行目:unified memoryでは最後に同期を取っています。
リスト4-4-1 Ex成分の更新(updateEx.cu)
1 __host__ __device__
2 static void updateEx_(
3 int64_t n, int nj, int nk,
4 float *ex, float *hy, float *hz,
5 float c1, float c2, float ryn, float rzn)
6 {
7 ex[n] = c1 * ex[n]
8 + c2 * (ryn * (hz[n] - hz[n - nj])
9 - rzn * (hy[n] - hy[n - nk]));
10 }
11
12 __global__
13 static void updateEx_gpu(
14 int imin, int jmin, int kmin, int imax, int jmax, int kmax, int ni, int nj, int nk, int n0,
15 float *ex, float *hy, float *hz, unsigned char *iex,
16 float *c1, float *c2, float *ryn, float *rzn)
17 {
18 const int i = imin + threadIdx.z + (blockIdx.z * blockDim.z);
19 const int j = jmin + threadIdx.y + (blockIdx.y * blockDim.y);
20 const int k = kmin + threadIdx.x + (blockIdx.x * blockDim.x);
21 if ((i < imax) &&
22 (j <= jmax) &&
23 (k <= kmax)) {
24 const int64_t n = (i * ni) + (j * nj) + (k * nk) + n0;
25 updateEx_(
26 n, nj, nk,
27 ex, hy, hz,
28 c1[iex[n]], c2[iex[n]], ryn[j], rzn[k]);
29 }
30 }
31
32 static void updateEx_cpu(
33 int imin, int jmin, int kmin, int imax, int jmax, int kmax, int ni, int nj, int nk, int n0,
34 float *ex, float *hy, float *hz, unsigned char *iex,
35 float *c1, float *c2, float *ryn, float *rzn)
36 {
37 for (int i = imin; i < imax; i++) {
38 for (int j = jmin; j <= jmax; j++) {
39 for (int k = kmin; k <= kmax; k++) {
40 const int64_t n = (i * ni) + (j * nj) + (k * nk) + n0;
41 updateEx_(
42 n, nj, nk,
43 ex, hy, hz,
44 c1[iex[n]], c2[iex[n]], ryn[j], rzn[k]);
45 }
46 }
47 }
48 }
49
50 void updateEx()
51 {
52 if (GPU) {
53 dim3 grid(
54 CEIL(kMax - kMin + 1, updateBlock.x),
55 CEIL(jMax - jMin + 1, updateBlock.y),
56 CEIL(iMax - iMin + 0, updateBlock.z));
57 updateEx_gpu<<<grid, updateBlock>>>(
58 iMin, jMin, kMin, iMax, jMax, kMax, Ni, Nj, Nk, N0,
59 d_Ex, d_Hy, d_Hz, d_iEx,
60 d_C1, d_C2, d_RYn, d_RZn);
61 if (UM) cudaDeviceSynchronize();
62 }
63 else {
64 updateEx_cpu(
65 iMin, jMin, kMin, iMax, jMax, kMax, Ni, Nj, Nk, N0,
66 Ex, Hy, Hz, iEx,
67 C1, C2, RYn, RZn);
68 }
69 }
Mur吸収境界条件はリスト4-4-2のようになります。
35,51,67行目のように1次元配列を1次元のblockとgridに分割しています。
リスト4-4-2 Mur吸収境界条件(murH.cu)
1 __host__ __device__
2 static void murh(real_t *h, mur_t *q, int64_t ni, int64_t nj, int64_t nk, int64_t n0)
3 {
4 const int64_t m0 = (ni * q->i) + (nj * q->j) + (nk * q->k) + n0;
5 const int64_t m1 = (ni * q->i1) + (nj * q->j1) + (nk * q->k1) + n0;
6
7 h[m0] = q->f + q->g * (h[m1] - h[m0]);
8 q->f = h[m1];
9 }
10
11
12 __global__
13 static void murh_gpu(
14 int64_t num, real_t *h, mur_t *fmur,
15 int64_t ni, int64_t nj, int64_t nk, int64_t n0)
16 {
17 const int64_t n = threadIdx.x + (blockIdx.x * blockDim.x);
18 if (n < num) {
19 murh(h, &fmur[n], ni, nj, nk, n0);
20 }
21 }
22
23
24 static void murh_cpu(
25 int64_t num, real_t *h, mur_t *fmur,
26 int64_t ni, int64_t nj, int64_t nk, int64_t n0)
27 {
28 for (int64_t n = 0; n < num; n++) {
29 murh(h, &fmur[n], ni, nj, nk, n0);
30 }
31 }
32
33
34 void murH(int64_t num, mur_t *fmur, real_t *h)
35 {
36 assert(num > 0);
37 if (GPU) {
38 murh_gpu<<<(int)CEIL(num, murBlock), murBlock>>>(
39 num, h, fmur,
40 Ni, Nj, Nk, N0);
41 if (UM) cudaDeviceSynchronize();
42 }
43 else {
44 murh_cpu(
45 num, h, fmur,
46 Ni, Nj, Nk, N0);
47 }
48 }
PML吸収境界条件の内、例えばEx成分についてはリスト4-4-3のようになります。
60行目のように1次元配列を1次元のblockとgridに分割しています。
リスト4-4-3 PML吸収境界条件(Ex成分, pmlEx.cu)
1 __host__ __device__
2 static void pmlex(
3 int64_t n, int64_t nj, int64_t nk,
4 float *ex, float *hy, float *hz, float *exy, float *exz, float4 f)
5 {
6 *exy = (*exy + (f.x * (hz[n] - hz[n - nj]))) * f.z;
7 *exz = (*exz - (f.y * (hy[n] - hy[n - nk]))) * f.w;
8 ex[n] = *exy + *exz;
9 }
10
11 __global__
12 static void pmlex_gpu(
13 int ny, int nz,
14 int64_t ni, int64_t nj, int64_t nk, int64_t n0,
15 float *ex, float *hy, float *hz, float *exy, float *exz,
16 int l, int64_t numpmlex,
17 pml_t *fpmlex, float *rpmle, float *ryn, float *rzn, float *gpmlyn, float *gpmlzn)
18 {
19 int64_t n = threadIdx.x + (blockIdx.x * blockDim.x);
20 if (n < numpmlex) {
21 const int i = fpmlex[n].i;
22 const int j = fpmlex[n].j;
23 const int k = fpmlex[n].k;
24 const int m = fpmlex[n].m;
25 const float ry = (m != PEC) ? ryn[MIN(MAX(j, 0), ny )] * rpmle[m] : 0;
26 const float rz = (m != PEC) ? rzn[MIN(MAX(k, 0), nz )] * rpmle[m] : 0;
27 const int64_t nc = (ni * i) + (nj * j) + (nk * k) + n0;
28 pmlex(
29 nc, nj, nk,
30 ex, hy, hz, &exy[n], &exz[n],
31 make_float4(ry, rz, gpmlyn[j + l], gpmlzn[k + l]));
32 }
33 }
34
35 static void pmlex_cpu(
36 int ny, int nz,
37 int64_t ni, int64_t nj, int64_t nk, int64_t n0,
38 float *ex, float *hy, float *hz, float *exy, float *exz,
39 int l, int64_t numpmlex,
40 pml_t *fpmlex, float *rpmle, float *ryn, float *rzn, float *gpmlyn, float *gpmlzn)
41 {
42 for (int64_t n = 0; n < numpmlex; n++) {
43 const int i = fpmlex[n].i;
44 const int j = fpmlex[n].j;
45 const int k = fpmlex[n].k;
46 const int m = fpmlex[n].m;
47 const float ry = (m != PEC) ? ryn[MIN(MAX(j, 0), ny )] * rpmle[m] : 0;
48 const float rz = (m != PEC) ? rzn[MIN(MAX(k, 0), nz )] * rpmle[m] : 0;
49 const int64_t nc = (ni * i) + (nj * j) + (nk * k) + n0;
50 pmlex(
51 nc, nj, nk,
52 ex, hy, hz, &exy[n], &exz[n],
53 make_float4(ry, rz, gpmlyn[j + l], gpmlzn[k + l]));
54 }
55 }
56
57 void pmlEx()
58 {
59 if (GPU) {
60 pmlex_gpu<<<(int)CEIL(numPmlEx, pmlBlock), pmlBlock>>>(
61 Ny, Nz,
62 Ni, Nj, Nk, N0,
63 d_Ex, d_Hy, d_Hz, d_Exy, d_Exz,
64 cPML.l, numPmlEx,
65 d_fPmlEx, d_rPmlE, d_RYn, d_RZn, d_gPmlYn, d_gPmlZn);
66 if (UM) cudaDeviceSynchronize();
67 }
68 else {
69 pmlex_cpu(
70 Ny, Nz,
71 Ni, Nj, Nk, N0,
72 Ex, Hy, Hz, Exy, Exz,
73 cPML.l, numPmlEx,
74 fPmlEx, rPmlE, RYn, RZn, gPmlYn, gPmlZn);
75 }
76 }
リスト4-4-4に平均電磁界を計算する関数を示します。
ソースコードの説明
2行目:関数"average_e"は指定したセルの中心の電界3成分の絶対値の和を返します。
23行目:関数"average_h"は指定したセルの中心の磁界3成分の絶対値の和を返します。
46-48行目:blockを(Z,Y)方向の2次元、gridを(Z,Y,X)方向の3次元としています。
50行目:blockの大きさ(=スレッド数)を求めます。
51行目:スレッド番号を求めます。
52行目:ブロック番号を求めます。
60,68行目:スレッドの和(全体から見たら部分和)をreductionで求めます。
94-96行目:shared memoryは全スレッドで共有されるメモリーです。
reductionで必要になります。
shared memoryの大きさをexecution configulationの第3引数で渡します。
このときGPU側では44行目のように"extern __shared__"を付けます。
103-109行目:CPUで全体の和(=部分和の和)を計算します。
リスト4-4-4 平均電磁界(average.cu)
1 __host__ __device__
2 static float average_e(float *ex, float *ey, float *ez, int i, int j, int k, param_t *p)
3 {
4 return
5 fabsf(
6 + ex[LA(p, i, j, k )]
7 + ex[LA(p, i, j + 1, k )]
8 + ex[LA(p, i, j, k + 1)]
9 + ex[LA(p, i, j + 1, k + 1)]) +
10 fabsf(
11 + ey[LA(p, i, j, k )]
12 + ey[LA(p, i, j, k + 1)]
13 + ey[LA(p, i + 1, j, k )]
14 + ey[LA(p, i + 1, j, k + 1)]) +
15 fabsf(
16 + ez[LA(p, i, j, k )]
17 + ez[LA(p, i + 1, j, k )]
18 + ez[LA(p, i, j + 1, k )]
19 + ez[LA(p, i + 1, j + 1, k )]);
20 }
21
22 __host__ __device__
23 static float average_h(float *hx, float *hy, float *hz, int i, int j, int k, param_t *p)
24 {
25 return
26 fabsf(
27 + hx[LA(p, i, j, k )]
28 + hx[LA(p, i + 1, j, k )]) +
29 fabsf(
30 + hy[LA(p, i, j, k )]
31 + hy[LA(p, i, j + 1, k )]) +
32 fabsf(
33 + hz[LA(p, i, j, k )]
34 + hz[LA(p, i, j, k + 1)]);
35 }
36
37 // GPU
38 __global__
39 static void average_gpu(
40 int nx, int ny, int nz, int imin, int imax,
41 float *ex, float *ey, float *ez, float *hx, float *hy, float *hz,
42 float *sume, float *sumh)
43 {
44 extern __shared__ float sm[];
45
46 const int i = imin + blockIdx.z;
47 const int j = threadIdx.y + (blockIdx.y * blockDim.y);
48 const int k = threadIdx.x + (blockIdx.x * blockDim.x);
49
50 const int nthread = blockDim.x * blockDim.y;
51 const int tid = threadIdx.x + (threadIdx.y * blockDim.x);
52 const int bid = blockIdx.x + (blockIdx.y * gridDim.x) + (blockIdx.z * gridDim.x * gridDim.y);
53
54 if ((i < imax) && (j < ny) && (k < nz)) {
55 sm[tid] = average_e(ex, ey, ez, i, j, k, &d_Param);
56 }
57 else {
58 sm[tid] = 0;
59 }
60 reduction_sum(tid, nthread, sm, &sume[bid]);
61
62 if ((i < imax) && (j < ny) && (k < nz)) {
63 sm[tid] = average_h(hx, hy, hz, i, j, k, &d_Param);
64 }
65 else {
66 sm[tid] = 0;
67 }
68 reduction_sum(tid, nthread, sm, &sumh[bid]);
69 }
70
71 // CPU
72 static void average_cpu(float *sum)
73 {
74 sum[0] = 0;
75 sum[1] = 0;
76 for (int i = iMin; i < iMax; i++) {
77 for (int j = 0; j < Ny; j++) {
78 for (int k = 0; k < Nz; k++) {
79 sum[0] += average_e(Ex, Ey, Ez, i, j, k, &h_Param);
80 sum[1] += average_h(Hx, Hy, Hz, i, j, k, &h_Param);
81 }
82 }
83 }
84 }
85
86 void average(double fsum[])
87 {
88 float sum[2];
89
90 // sum
91 if (GPU) {
92 cudaMemcpyToSymbol(d_Param, &h_Param, sizeof(param_t));
93
94 int sm_size = sumBlock.x * sumBlock.y * sizeof(float);
95 average_gpu<<<sumGrid, sumBlock, sm_size>>>(
96 Nx, Ny, Nz, iMin, iMax, d_Ex, d_Ey, d_Ez, d_Hx, d_Hy, d_Hz, m_sumE, m_sumH);
97
98 // device to host
99 size_t size = sumGrid.x * sumGrid.y * sumGrid.z * sizeof(float);
100 cudaMemcpy(h_sumE, d_sumE, size, cudaMemcpyDeviceToHost);
101 cudaMemcpy(h_sumH, d_sumH, size, cudaMemcpyDeviceToHost);
102
103 // partial sum
104 sum[0] = 0;
105 sum[1] = 0;
106 for (int i = 0; i < size / sizeof(float); i++) {
107 sum[0] += m_sumE[i];
108 sum[1] += m_sumH[i];
109 }
110 }
111 else {
112 average_cpu(sum);
113 }
114
115 // average
116 fsum[0] = sum[0] / (4.0 * Nx * Ny * Nz);
117 fsum[1] = sum[1] / (2.0 * Nx * Ny * Nz);
118 }
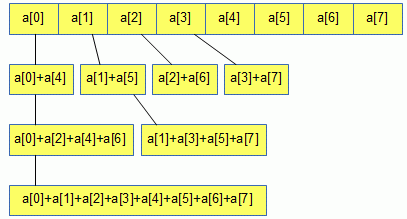
リスト4-4-5にreduction関数を示します。
reductionとはN個の演算を複数のスレッドの共同作業でlog2N回で求めるGPUの操作です。
引数"s"がshared memoryでありスレッド間で共有されます。
図4-4-1にreductionの概念図を示します。
詳細についてはCUDAのサンプルプログラム"reduction"を参考にして下さい。
リスト4-4-5 reduction関数
1 __device__
2 void reduction_sum(int tid, int n, float *s, float *sum)
3 {
4 __syncthreads();
5
6 for (int stride = (n + 1) >> 1; n > 1; stride = (stride + 1) >> 1, n = (n + 1) >> 1) {
7 if (tid + stride < n) {
8 s[tid] += s[tid + stride];
9 }
10 __syncthreads();
11 }
12
13 if (tid == 0) {
14 *sum = s[0];
15 }
16 }
図4-4-1 reductionの概念図
表4-4-1にGPU版の計算時間を示します。
novectorモードの方が少し速くなります。
これからGPUでは使用メモリーの少ないnovectorモードを推奨します。
なお、ベンチマーク400のvectorモードはメモリー不足のために計算時間が増えています。
| ベンチマーク | novector | vector |
|---|---|---|
| 100 | 2.0秒 | 2.7秒 |
| 200 | 16.5秒 | 19.3秒 |
| 300 | 54.0秒 | 63.4秒 |
| 400 | 126.1秒 | 240.0秒 |